0 说点废话(讲一下怎么找到这个文章的)
2022年7月16日
在床上百无聊耐的看视频 突然看到这样的东西

https://www.bilibili.com/video/BV1EY411K7wt
嗯嗯 我就去这个网站试了试
https://openknowledgemaps.org/
查了查 我留下的二课题 知识追踪(cool)

发现了一篇 2022-4-1 号的 中文的一篇综述 就很开心
0.1 废话之后
根据 实验室要求
9\21
俺 又根据一篇新的中文综述 来弥补这次文章的更新
文章名: Review of Knowledge Tracing Model for Intelligent Education
doi号: https://doi.org/10.3778/j.issn.1673-9418.2111054
这次 更新 bkt更新 数据集更新 加 模型原型 GKT 模型解释
1. 前言-知识追踪是啥
KT算法将学生的知识掌握程度随着时间的推移建模预测,从而能够准确地预测学生在未来互动中的表现据此有针对性地为学生订制不同的学习路线,提升学习效率.学生通过在线学习平台进行学习交互,形成答题行为时间序列,KT算法通过对学习者和序列联合建模,预测其对于新知识的认知概率分布,进一步推理出学习者的技能和认知水平。
2. KT问题定义以及比较
常用缩写:
KT knowledge tracing
KC 是 知识点、概念、技能或者项目等通用术语
2.1 定义

2.2 数据集
ASSISTments Data是KT领域最为经典的数据集,其中ASSISTments2009数据集 是绝大多数KT模型的标准数据集;EdNet[8] 发布于2019年,是KT领域最新的数据集,提供了超过1亿条 学习者交互记录;Synathetic是 DKT模型所附带的数据集,包括了超过 20万条学习记录信息;其他数据集包括:Junyi15,algebra 2006 2007及Statics2011等.
| dataset | Website | Field | Records/k |
|---|---|---|---|
| ASSISTments2009 | https://sites.google.com/site/assistmentsdata/datasets | Math | 325 |
| ASSISTments2012 | https://sites.google.com/site/assistmentsdata/home/2012-13-school-data-with-affect | Math | 2541 |
| ASSISTments2015 | https://sites.google.com/site/assistmentsdata/home/2015-assistments-skill-builderdata | Math | 683 |
| ASSISTments2017 | https://sites.google.com/view/assistmentsdatamining/dataset | Math | 942 |
| KDD Cup2010 | https://pslcdatashop.web.cmu.edu/KDDCup/downloads.jsp | 607 | |
| Ednet | https://github.com/riiid/ednet | English | 131 441 |
| Junyi15 | https://pslcdatashop.web.cmu.edu/DatasetInfo?datasetId=1275 | Math | 2 500 |
| algebra 2006 2007 | https://pslcdatashop.web.cmu.edu/KDDCup/downloads.jsp | Math | 180 |
| Synathetic-5 | https://github.com/chrispiech/DeepKnowledgeTracing/tree/master/data/synthetic | Math | 200 |
| Statics2011 | https://pslcdatashop.web.cmu.edu/DatasetInfo?datasetId=507 | Engineering | 361 |
| slepemapy.cz | https://www.fi.muni.cz/adaptivelearning/?a=data | 10087 |
2.3 常用评估指标

2.4 模型大类
| 模型大类 | 提出时间 | 原理 | 优势 | 局限性 | 适用场景 |
|---|---|---|---|---|---|
| BKT | 1994 | HMM | 模型简单,具有可靠的教学可解释性 | 依赖教育专家标注矩阵以及简化假设 | 适用于根据先验知识状态自动给每个学生推荐题目的场景,需要先得到先验分布 |
| FAM | 2006 | logistic | 模型简单,增加练习-kc的q矩阵,具有可解释性 | 依赖专家标注矩阵,需要手工输入特征 | 适用于从历史数据中学习一般参数对学生建模进而预测作答表现的场景,需要教育专家标注的 Q矩阵 |
| DKT | 2015 | RNN/Lstm | 性能好,无需专家对KC进行编码 | 模型复杂,训练规模较大,不具备可解释性 | 适用于不需要解释学生知识状态、只需给出学生学习结果情况的场景,如智能组卷场景 |
| DKVMN | 2017 | MANN | 网络相对简单,提高模型记忆能力 | 参数多 训练规模大 | 适用于学生日常练习记录交互日 志,在练习-KC 单一映射的场景下快速建立学生知识状态掌握情况 |
| GKT | 2019 | GNN | 建模底层 KC 之间的关系 | 实际教学中 KC 划分粒度不一致直接影响学生知识状态评估性能 | 适用于练习-KC 之间存在多重复杂关系的场景,对学生知识状态掌握情况的细节要求较高,具备一定的可解释性 |
KT过程分析
基于logistic回归方法
项目反应理论(IRT)
项目反应理论(IRT)该理论假设学习者的学习能力不随时间和实践变化。(该理论认为 只有答会高水平的题目 才能证明学生是高水平的)
项目反应理论[29] 是一种现代心理测量理论,其中 “项目”(item)指的是学生试卷中的题目,“项目反应” (item response)为学生在具体题目上的作答情况。 简言之,IRT 就是建立在学生能力和作答正确率的关系上,影响学生在项目上作答结果的主要因素有两个:其一是学生本身的能力水平;其二是试题项目的测量学属性,如项目难度、区分度和猜测性等
举个例子:
考生答对的题目难度是判断考生能力的标准。某考生答对10道难度为1的题目,获得的能力值依然是1,另一考生答对1道难度为8的题目,能力值则为8
其中rasch模型 使用难度描述 输入模型的问题
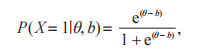
其中,θ 代表学习者的学习能力;b 代表问题的难度 .Rasch 模型在可解释性、问题区分性等方面性能优越,GHOSH等通过在深度模型中使用Rasch编码,提高了DKT的可解释性,取得了卓越的预测性能.
深度技术下 IRT模型
| 模型名 | 论文名 | 干啥 | 年份 |
|---|---|---|---|
| Deep ⁃IRT | Deep ⁃ IRT:make deep learning based knowledge tracing explainable using item response theory | 它是 IRT 模型与 DKVMN 模型的结合 . | 2022 |
| EKPT | Learning or forgetting?A dynamic approach for tracking the knowledge proficiency of student | 提出知识熟练度追踪(KPT)模型和练习关联的知识熟练度(EKPT)模型,应用于知识估计、分数预 测和诊断结果可视化三个重要任务. | 2020 |
| KTMs | Knowledge tracing machines:factorization machines for knowledge tracing | 综合IRT,AFM,PFA等模型,提出了知识追踪机(KTMs)框架,KTMs利用所有特征的稀疏权值集,对学习者答题结果的概率进行建模. | 2019 |
基于知识追踪的因子分析
因子分析模型与 IRT模型相似,但是它们会通过学习知识水平的参数估计学生正确回答题目的概率。学习因子分析(learning factors analysis,LFA)源于学习曲线,是一种半自动化的方法,改进由统计 模型、人类专业知识与组合检索组成的认知模型。学习曲线证明了错误率与练习次数呈幂次关系,但 没有考虑到学生数量的庞大性,以及一个题目可能包含多种 KC。因此,LFA适应并扩展了学习曲线,假设不同学生的学习率相同
LFA模型的标准形式可参见式

性能因子分析(performance factors analysis,PFA)是 LFA 的一种改进,LFA 对练习时间很敏感,但是忽略了学生的正确和错误回答。PFA 假设每个学生都 是一个独特的个体,学生的学习不是仅仅通过相同的练习频率积累,每个学生也会通过其自身正确或错误的尝试来学习。
PFA 在LFA的基础上 进行了调整

Vie 等人采用因子分解机(factorization machines,FM)将其分类形式用于学生建模,并提出了知识追踪机(knowledge tracing machines, KTM),使用 FM 来交互每个特征进行预测。该方法将有关题 目与学生的侧面信息编码到参数模型中,即使观察到的学生数据是稀疏的情况下,也可以快速准确地 估计学生的知识状态。对观察到答题正确与否的二进制输出概率进行建模,对于每个题目回答正确的概率进行验证。但是,KTM 存在冷启动问题以及依 赖 KC的重复学习,对于一些不经常练习的 KC,KTM可能退化为 IRT。为了解决这些问题,Lai等人[35] 提出 了一种循环知识追踪机(recurrent knowledge tracing machine,RKTM)来改进 KTM。该方法根据学生的知识状态,在时间上丰富了 KTM 和难度、学生能力、技能以及学生技能实践历史的编码,利用其处理知 识 状 态 的 RNN 结 构 捕 捉 KC 之 间 的 关 系 ,以 便RKTM 可以找到相似的KC 并收集其相似信息以提供更精准的预测。
| 模型 | 方法概述 | 局限性 | 发表年份 |
|---|---|---|---|
| LFA | 源于学习曲线的一种半自动化的方法 | 对练习时间具有敏感性 | 2006 |
| PFA | LFA的改进方法,考虑题目的正误反应数量的学习累积 | 不能处理知识点之间的内在依赖性 | 2009 |
| IRT | 基于 IRT理论,为学生能力和题目难度建立参数模型 | 学生的能力水平在学习过程中是固定的 | 2018 |
| KTM | 利用 FMs将传统的 Logistic模型推广到更高的维度 | 冷启动问题,不能准确代表之前的学习序列 | 2019 |
| RKTM | 引入学生知识状态,与当前学习场景交互 | 特征提取困难,参数较多,增加了学习复杂度 | 2021 |
学习认知机制和遗忘机制
认知机制
WANG等提出了一种通用的神经认知诊断框架,摒弃人工特征,将神经网络集成到复杂的非线性交互模型中,解决认知诊断问题,并且结合CNN,提出了Neural CDM+模型,通过自动提取系统中的知识点信息,补充知识点相关度矩阵,避免了主观性甚至错误.
遗忘机制
DKT模型使用RNN一定程度上实现了对记忆过程模拟,但是仍然没有真正意义上模拟人类思维习惯.
| 模型 | 论文名 | 方法 | 年份 |
|---|---|---|---|
| LPKT | Learning Process-consistent Knowledge Tracing | 加了个遗忘层 主要是sigmoid | 2021 |
| DKVMN | Dynamic key ⁃ value memory networks for knowledge tracing | 过类似于计算机内存管理的方式,建立知识记忆遗忘矩阵,在模型可解释性上取得了很大的进步 | 2017 |
| CKT | Context-aware attentive knowledge tracing | 基于Transformer的模型框架 上引入了注意力衰减机制,模拟全局遗忘行为,从而取得了较好的模型效果 | 2020 |
KT方法
BKT

特点
标准BKT模型建模过程中将知识点设置为“永不忘记”,并且假设一个题目只对应一个知识点(按道理来说 一个题目是对应多个知识点的)
在其中有几种概率
2.1 P ( L)是初始知识状态下学生掌握相关知识点的概率
2.2 P (T )为经过练习后学生掌握目标知识点的概率
2.3 P (G)表示学生猜对答案的概率(有趣)
2.4 P ( S)为学生掌握知识点但做错题目的概率

结合个性化的扩展模型
由于 BKT 模型并没有考虑到学生背景知识的个体化估计、先验知识的参数化等
局限性:依赖于简化的假设, 如每道题目仅涉及一 个 KC,学习过程中不存在遗忘情况等
| 模型 | 论文 | 方法 | 年份 |
|---|---|---|---|
| modeling individalization in a bayesian networks inplementation of knowledge tracing | 为每个学生设计不同初始背景的知识状态 | 2010 | |
| the impact on individalizing student models on necessary practice opportunities | 设计学生导向模型,提高个体性差异 | 2012 | |
| Individualized Bayesian knowledge tracing models | 将模型参数划分为知识部分和学生部分提高模型性能 | 2013 | |
| Traditional knowledge tracing models for clustered students | 基于聚类学生进行贝叶斯知识追踪 | 2020 |
结合知识相关性
BKT 对每个 KC 进行单独建模,导致模型对习题库以及 KC 与习题关联模型的依赖性较强,无法捕捉到不同 KC 之间的相关性。如果知识模型粒度太粗或太细,都会使 BKT 模型难以准确评估学生的知识状态;如果学生连续处理几道与同一个 KC 相关的类似习题,可能会对该学生后面的表现产生积极影响
局限性:需要设置阈值,而不 同类型 KC 需要不一 样的阈值范围以及设置依据
| 模型 | 论文 | 方法 | 年份 |
|---|---|---|---|
| Using similarity to the previous problem to improve Bayesian knowledge tracing | 使用 DBN表示 KC拓扑结构 | 2014 | |
| Structured knowledge tracing models for student assessment on coursera | 考虑到题目相似性的 BKT-ST模型 | 2014 | |
| Dynamic Bayesian networks for student modeling | 基于知识状态的层次性和时间特性进行建模 | 2016 | |
| Spectral Bayesian knowledge tracing | 利用 DBK在单个模型中联合考虑不同的 KC | 2017 |
结合节点状态
BKT 是以一种二进制变量概率分布追踪并更新学生对某个 KC 潜在掌握情况的一阶 HMM,该模型 假设一个理想的无噪声环境且参数具有简并性。这显然是与实际情况不符的
局限性: 参数较多,计算量大,复杂度高
| 模型 | 论文 | 方法 | 年份 |
|---|---|---|---|
| Extending knowledge tracing to allow partial credit: using continuous versus binary nodes | 采用 0到 1的连续型表示法,细化学生的知识状态 | 2013 | |
| Proceedings of the 8th International Conference on Educational Data Mining, | 用 3-gram代替二元节点状态的 Spectral BKT模型 | 2015 | |
| three learning states Bayesian knowledge tracing model | 采用三支决策的思想改进二进制节点状态 | 2018 |
现实结合
局限性:先验概率的确定存在主观性,简单的模型很难纳入实际情况的复杂性
| 模型 | 论文 | 方法 | 年份 |
|---|---|---|---|
| introducing item difficulty to the knowledge tracing model | 将题目的难度系数引入 BKT | 2011 | |
| Affect and inference in Bayesian knowledge tracing with a robot tutor | 融入学生的情感状态 | 2015 | |
| Dynamic knowledge tracing through data driven recency weights | 引入学生答题情况近期率权重的 MS-BKT模型,细化学生知识状态 | 2020 | |
| 融合行为和遗忘因素的贝叶 斯知识追踪模型研究 | 融合了学生的学习行为与遗忘因素 | 2021 |
DKT
改进
- 可解释性问题改进
深度学习模型不具备类似传统模型的可解释性,很难弄清楚隐藏状态是如何代表学生的知识状态的,无法从隐藏 状态确定学生的知识掌握水平
On the interpretability of deep learning based models for knowledge tracing[J]. arXiv: 2101.11335, 2021.
- 缺少学习特征问题改正
DKT 模型的输入仅仅是练习标签的 one-hot 编码,排除了许多其他丰富 的信息和特性,如练习内容、学生尝试答题的次数以及答题持续时间等,而是将所有学生的表现平均化, 因此被认为不足以进行适应性学习
基于RNN的KT
整体来讲,基于RNN结构的追踪模型在性能和可用性方面大幅度超越了传统模型,但是在解释性上略显不足.
| 模型 | 论文 | 方法 | 年份 |
|---|---|---|---|
| DKT-DSC | Deep knowledge tracing and dynamic student classification for knowledge tracing | 通过在每个时间间隔内将学生分组,预测学生的学习效果 | 2018 |
| .。。 | Incorporating features learned by an enhanced deep knowledge tracing model for stem/non-stem job prediction | 采用DKT进行知识状态预测,证明了DKT模型在实际工作中的有效性. | 2019 |
| EERNN | Exercise⁃enhanced sequential modeling for student performance prediction | 通过追踪学生的练习记录和相应练习的文本内容,提出了一个通用的练习增强循环神经网络(EERNN)框架 | 2018 |
基于注意力的DKT
通过注意力机制,可以在过去的交互序列中寻找到与当前问题相关的重信息,从而做出更为准确的预测,并且证明了基于 Transformer的模型比基于 RNN的模型在运算速度上快了一个数量级.
| 模型 | 论文 | 效果 | 年份 |
|---|---|---|---|
| transformer | A self ⁃ attentive model for knowledge tracing | 必然伴随着对过去相关练习交互的回忆 | 2019 |
| 双向transformer | Towards an appropriate query,key,and value computation for knowledge tracing | 将练习序列和回答序列分别进行编码,从而寻找到了更为合适的 Query | 2020 |
| Saint+ | Saint+:integrating temporal features for EdNet correctness prediction | 将经过时间、滞后时间两个特征编码与学生答题响应的编码进行结合,从而增强了 模型的预测精度. | 2021 |
基于hawkes过程的DKT
https://blog.csdn.net/guanlily123/article/details/100145889
Hawkes过程则假设过去事件会在一定程度上提高未来事件发生的概率,并且这种影响会随着时间指数衰减,这种思想比较符合认知遗忘规律下的学习者能力.
| 模型 | 论文 | 效果 | 年份 |
|---|---|---|---|
| LSTM | The neural Hawkes process:a neurally self⁃modulating multivariate point process | 利用Hawkes过程对长短期记忆(LSTM)节点的时间效应(遗忘效应)进行衰减处理.KT领域的学习者交互过程可以被看作是一系列的连续事件流,但是泊松过程假定事件相互独立,并不符合多知识点状态下学习者交互的逻辑 | 2017 |
| Hawkes Process | Temporal cross⁃effects in knowledge tracing | 定事件相互独立,并不符合多知识点状态下学习者交互的逻辑忘效应)进行衰减处理.KT领域的学习者交互过程可以被看作是一系列的连续事件流,但是泊松过程假 深入研究了不同知识点之间的时间交叉效应,并且提高了深度模型的可解释性 | 2021 |
GKT
知识关系– 使用图来表示知识关系(知识与知识之间具有复杂的逻辑关系)
局限性:计算密集型,易受数据集大小的限制,由于 KC 划分 粒度不一致,可能会直接 影响学生知识状态的评估 性能
| 模型名 | 论文 | 方法 | 年 |
|---|---|---|---|
| GKT | Graph-based knowledge tracing: modeling student proficiency using graph neural network | 利用 GNN构建 KC关系图 | 2019 |
| GIKT | GIKT: a graph- based interaction model for knowledge tracing | 利用 GCN提取练习-KC关系图中包含的高阶关系信息 | 2020 |
| HGKT | HGKT: introducing problem schema with hierarchical exercise graph for knowledge tracing | 结合练习之间的层次关系,建模练习学习依赖性 | 2020 |
| JKT | JKT: a joint graph convolutional network based deep knowledge tracing | 联合图卷积网络提取隐藏在“练习-KC”图中的深层隐式信息 | 2021 |
| DGMN | Deep graph memory networks for forgetting-robust knowledge tracing | 利用外部记忆结构的知识状态动态构建潜在 KC 及其 关系图,同时考虑遗忘行为 | 2021 |
| Peer ⁃inspired student performance prediction in interactive online question pools with graph neural network | 在 R-GCN 的基础上,利用学生互动过程,构建了“学生—互动—问题”网络,提出了 R2GCN 模型 | 2020 |
动态键值网络
由于 DKT 模型以隐藏状态代表学生对 KC 的掌握情况,无法详细输出学生对每个 KC的掌握程度, 并且 LSTM 将所有记忆存储在一个隐藏向量中,这使得 LSTM 很难准确地记录拥有数百个时间步长的序列。
Zhang 等人 借鉴 MANN,结合 BKT 和DKT 的优点提出 DKVMN 模型,该方法允许网络保留多个隐藏状态向量,分别进行读写。

| 模型名 | 方法 | 论文 | 年份 |
|---|---|---|---|
| DKVMN | 借鉴 MANN,利用静态、动态外部矩阵分别读写学生知识状态 | Dynamic key- value memory networks for knowledge tracing | 2017 |
| DKVMN-CA | 改进 DKVMN,支持人工标注概念树 | Concept- aware deep knowledge tracing and exercise recommendation in an online learning system | 2019 |
| LPKT | 采用 DKVMN,结合学生的知识现状,完善模型的遗忘机制 | Knowledge tracking model based on learning process | 2020 |
| DKVMN-LA | 引入学生学习能力与行为特征的多功能知识追踪算法 | Dynamic key-value memory networks with rich features for knowledge tracing | 2021 |
注意力机制
针对于 前四种kt方法是针对网络结构的一种既定改变,引入注意力机制是一种特殊的网络结构。
| 模型名 | 理由 | 方法 | 年份 |
|---|---|---|---|
| EERNNA | 首次考虑到练习文本的特征 | 双向lstm 提供嵌入文本特征,嵌入练习文本特征建模学生的学习过程 | 2018 |
| SAKT | 首次将 Transformer模型应用于知识追踪领域 | 基于自注意力机制建模学生的交互历史,减少无关练习对目标练习的影响 | 2019 |
| SAINT | 认为SAKT 模型的注意力层太浅且没有对 Q、K 与 V 进行充分发掘建模 | 改进 SAKT,基于深度自注意层建模练习和学生回答之间的关系 | 2020 |
| AKT | 完全依赖注意力 | 建模题目与回答的上下文感知,表示提取学生的猜测与失误特征 | 2020 |
| RKT | 引入了一个包含上下文信息的关系感知自注意力层,同时保持了自注意力机制的简单性和灵活性。 | 利用上下文信息来增强自注意力机制,采用对指数衰减核函数建模学生遗忘行为 | 2020 |
| EKTA | 改进 EERNNA,追踪学生对特定 KC的掌握程度 | 2021 | |
| MF-DAKT | 使用预训练方法来合并练习关系和难度水平信息丰富了模型的题目表示 | DAKT 从不同角度捕捉因子和因子相互作用中包含的信息 | 2021 |
| ATKT | DNN存在过拟合风险,导致泛化能力有限 | 利用高效注意力-LSTM 自适应聚合先前知识隐藏状态的信息,通过 AK增强模型的泛化能力 | 2021 |
benchmark

展望
本文作者对比讨论了目前主流的KT模型,分析了主流模型的优缺点.目前的研究主要针对知识点与题目间的关系进行建模,很少有研究从模型效果评价指标、学习潜力预测、深度记忆过程模拟等方面进行知识状态追踪和预测,同时也较少有对多知识点关系建模方法进行知识状态追踪的研究.通过分析KT领域目前主流的模型,梳理出KT领域未来的发展方向,从数据表征、认知建模、建模方法、解释及反馈方面对KT领域进行展望.
1)数据处理及数据表征.KT模型在运用输入数据方面越来越需要预处理、预训练操作.预训练模型在序列任务上表现出了良好的性能,采用可解释性较强的算法预处理输入数据变得越来越重要.比如使用Rasch编码预处理输入数据后,再进行注意力运算和模型预测,在模型性能和可解释性方面都取得了很好的效果 .在数据特征方面,引入学习者生物特征、更加丰富的习题特征都是未来重要的突破方向,KT模型应该向更高维度、更普适、更泛化的方向发展,如何对学习者的非结构性学习数据进行追踪也是重要的发展方向.
2)认知建模 .认知诊断和 KT分别应用于学习者静态数据分析和动态数据分析,但 KT模型内不应缺乏对学习者认知能力的建模.对于问题维度、知识点维度的建模不足以拟合学习者的知识状态变化,应在此基础上进一步对认知维度进行建模,从而在更高的维度上追踪学习者的状态变化情况.
3)模型方法及可解释性 .自从 DKT被提出以来,KT领域内的模型基本以深度模型为主,但越来越多的工作表明 DKT无法做到真正的动态自适应 KT.基于 RNN 的模型在数据拟合能力上逐步被以注意 力机制为核心的Transformer类模型超越,未来KT领域建模方法应该在注意力方向、图谱方向进一步发展.人脑记忆的形成过程中,人自身的注意力是重要的一环,这也是基于注意力机制模型结合遗忘建模取得不错效果的关键原因.知识图谱作为非结构化知识表征的重要手段,在KT领域有更进一步的潜力, 并且对于认知能力研究也可以加入图谱技术,从而在可解释性KT方向取得突破.