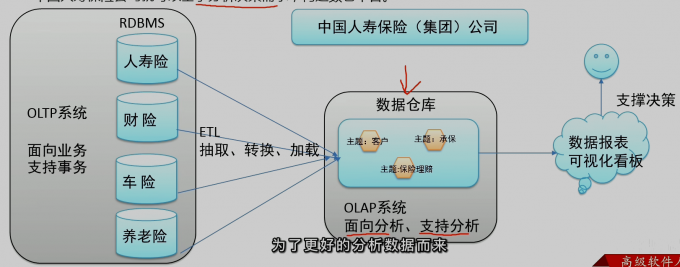
OLTP -> ETL (抽取 转换 加载)-> OLAP
数仓
数仓的主要特征
- 面向主题
主题是一个抽象的概念,是较高层次上数据综合、归类并进行分析利用的抽象。
- 集成性
主题相关的数据通常会分布在多个操作型系统中,彼此分散、独立、异构。需要集成到数仓主题下。
- 非易失性
也叫非易变性。数据仓库是分析数据的平台,而不是创造数据的平台。
- 时变性
数据仓库的数据需要随着时间更新,以适应决策的需要。
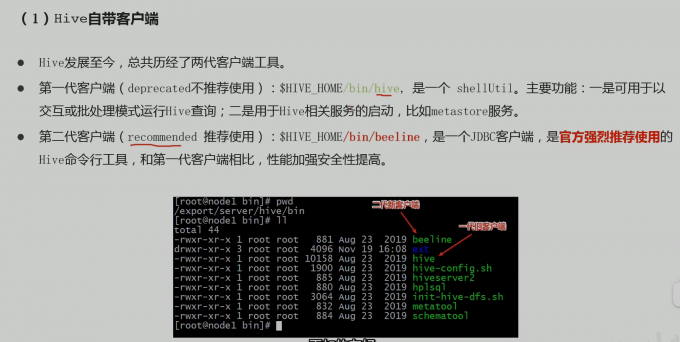
hive
开始
Apache Hive是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化数据文件映射为一张数据库表,基于表提供了一种类似SQL的查询模型,称为Hive查询语言(HQL),用于访问和分析存储在Hadoop文件中的大型数据集。
Hive核心是将HQL转换为MapReduce程序,然后将程序提交到Hadoop群集执行。
为什么使用
操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)避免直接写MapReduce,减少开发人员的学习成本支持自定义函数,功能扩展很方便,背靠Hadoop,擅长存储分析海量数据集
hive 与 hadoop之间的关系
Hive利用HDFS存储数据,利用MapReduce查询分析数据。
Hive的最大的魅力在于用户专注于编写HQL,Hive帮您转换成为MapReduce程序完成对数据的分析。
底层猜想
- 映射关系(文件和表之间的对应关系)
映射在数学上称为一种对应关系
在 hive中 映射指的是对 mysql文件 映射成表的功能
因此 映射信息专业的应该被称为 元数据信息(metadata)
- sql语法的解析
用户写完sql之后,hive需要针对sql进行语法校验,并且根据记录的元数据信息解读sql背后的含义,制定执行计
划。并且把执行计划转换成MapReduce程序来具体执行,把执行的结果封装返回给用户。
架构
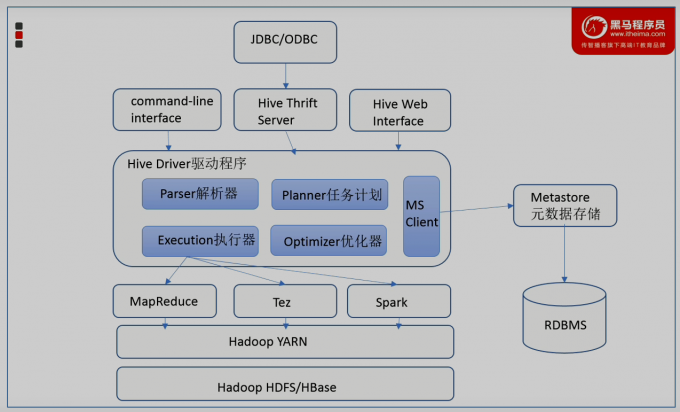
- 用户接口
包括CLI、JDBC/ODBC、WebGUI。其中,CLI(command line interface)为shell命令行;Hive中的Thrift服务器允许外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议。WebGUI是通过浏览器访问Hive。
- 元数据存储
通常是存储在关系数据库如mysql/derby中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
- 驱动程序
完成 HOQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储住HDPS 中,开仕随后有执行引擎调用执行。
- 执行引擎
Hive本身并不直接处理数据文件。而是通过执行引擎处理。当下Hive支持MapReduce、Tez、Spark3种执行引擎。
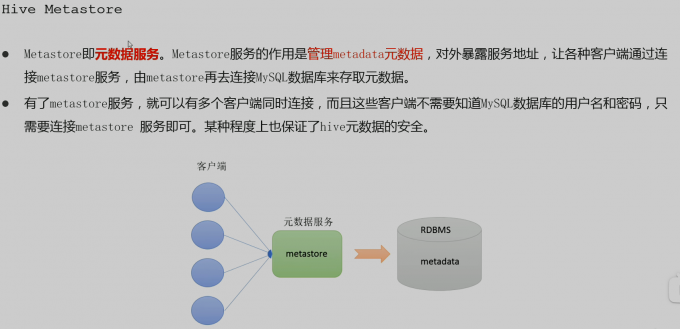
hive 元数据
元数据 为 描述数据的数据
- hive metadata
即为hive元数据
包含用Hive创建的database、table、表的位置、类型、属性,字段顺序类型等元信息。
元数据存储在关系型数据库中。如hive内置的Derby、或者第三方如MySQL等。
- metastore
即元数据服务 metastore 服务的作用时管理metadata元数据
- metastore 配置方式

- metastore远程模式
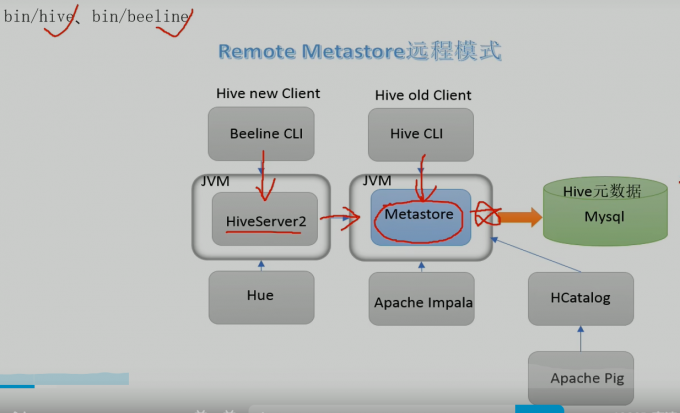
远程模式注意的点

启动
主要是 结构的奇怪
在hive 安装的服务器上 首先启动metastore服务 然后启动hiveserver2服务
metastore服务启动
- 前端启动
前台启动,进程会一直占据终端,ctrl + c结束进程,服务关闭。可以根据需求添加参数开启debug日志,获取详细日志信息,便于排错。
/export/server/apache-hive-3.1.2-bin/bin/hive –server metastore
- 后台启动
nohup /export/server/apache-hive-3.1.2-bin/bin/hive –service metastore &
1 | 结束进程方法 |
hiveserver2服务启动
hive很奇怪 必须启动完 第一代客户端之后 才能启动二代客户端
- 命令
nohup /export/server/apache-hive-3.1.2-bin/bin/hive –service hiveserver2 &
连接
/export/server/apache-hive-3.1.2-bin/bin/hive
node3 连接 node1 启动的服务
1 | 启动hive服务 |