2022/8/30日 开始
https://www.bilibili.com/video/BV1CU4y1N7Sh
课程的学习
预计花费时间两周
数据分析基本步骤
明确分析目的和思路
思路是使分析框架体系化,比如先分析什么,后分析什么,使各分析点之间具有逻辑联系,保证分析维度的完整性,分析结果的有效性以及正确性,需要数据分析方法论进行支撑;PEST分析法
数据收集
互联网公开数据
业务数据
日志数据
爬虫数据数据处理
数据预处理
数据清洗 数据转化 数据提取 数据计算
数据分析
数据分析方法 数据分析软件
数据展现
数据可视化 分析结果图表展示
报告撰写
数据分析报告是对整个数据分析过程的一个总结与呈现
把数据分析的起因、过程、结果及建议完整地呈现出来,供决策者参考
需要有明确的结论,最好有建议或解决方案
分布式与集群
共同点:多台机器
分布式: 多台机器每台机器上部署不同组件
集群:多台机器每台机器上部署相同组件
vimware
第一件事 是调整虚拟机 与 本机 是在同一个网段下面
vm中 是 编辑-》虚拟网络编辑器-》更改设置
win下 是 网络连接 -》vm8 -》tcpipv4 -》设置网段
挂起
类似软件冻结 再次开机恢复原来状态
快照
可以将虚拟机 恢复到我们之前设定好的状态 (几乎是一瞬间回复)
说实话 这个功能今天才知道 算是一个大杀器
ssh
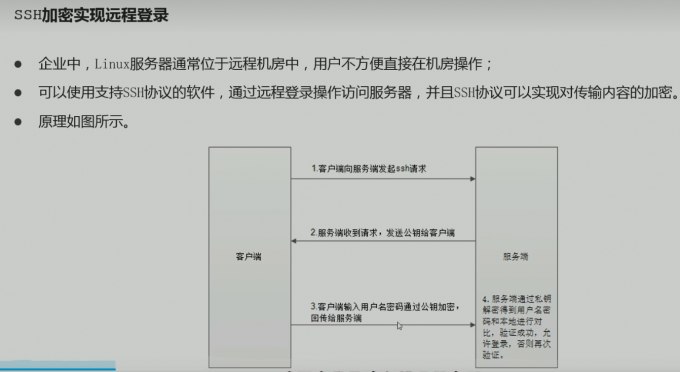
公钥私钥成双成对
都是服务器生成的
服务器将公钥给客户端 客户端使用公钥进行加密
最后服务器将加密数据用私钥进行解密 就完成了这个过程
linux 文件系统
操作系统中负责管理和存储文件信息的软件机构称为文件管理系统,简称文件系统;
文件系统的结构通常叫做目录树结构,从斜杠/根目录开始;
Linux号称“万物皆文件”,意味着针对Linux的操作,大多数时间是在针对Linux文件系统操作。
1 | ls 查看文件 |
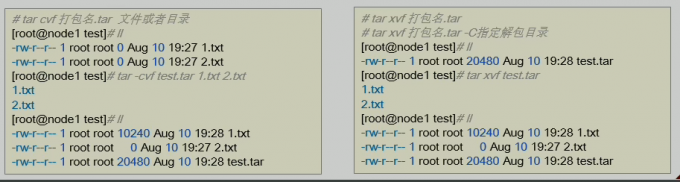
1 | 解压缩命令 tar |
1 | free 显示内存使用情况 |
vim编辑器
https://blog.csdn.net/qq_52914969/article/details/123026341
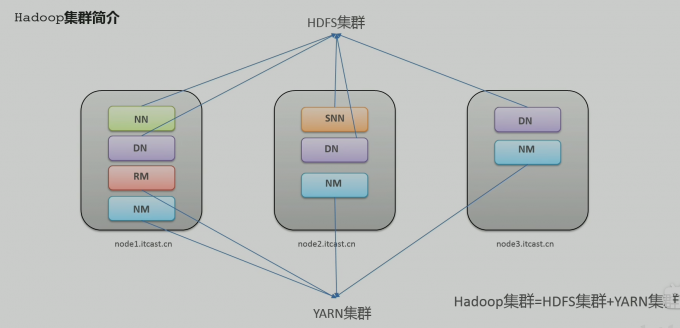
Apache Hadoop
hadoop集群包括两个
HDFS
YARN
两个集群 逻辑上分离 物理上在一起
两个集群 是标准的主从架构

hadoop 安装包目录结构
结构

配置文件
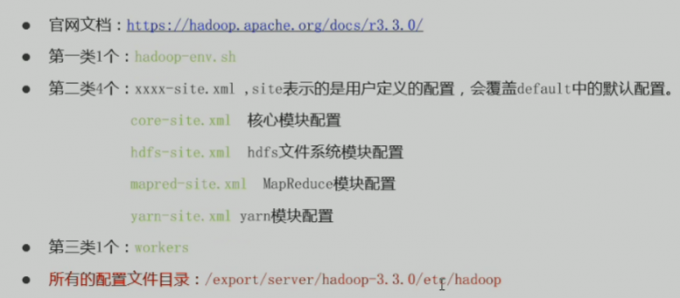
第一类 java路径 和 运行的进程
第二类 核心模块的配置 (hdfs mapreduce yarn) 外加 核心模块设置
第三类 表示 小弟从角色运行在什么机器上
将hadoop添加配置到环境变量
大G小o 来到最后一行进行编辑
然后 source /etc/profile 弄好配置文件
namenode format 初始化操作(只需要做一次)
hdfs namenode -format
本质上是初始化工作 进行hdfs清理和准备工作

成功的样子!

hadoop开启
- 开启脚本
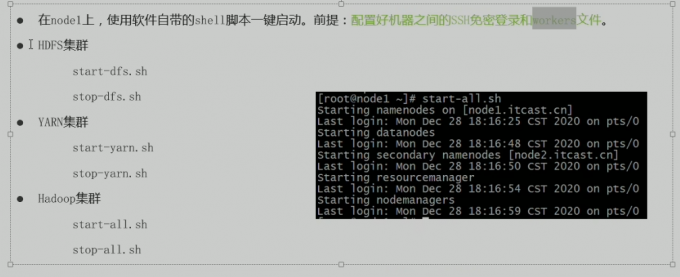
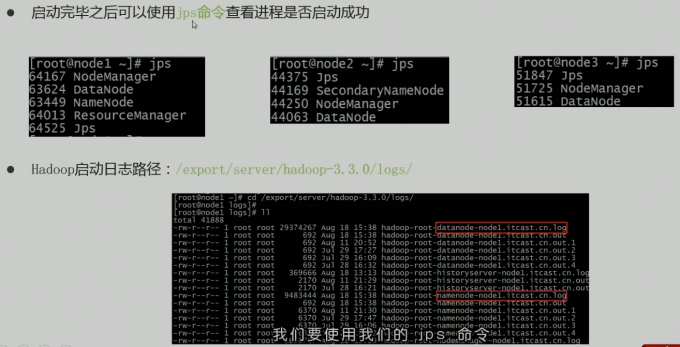
开启成功检测方法
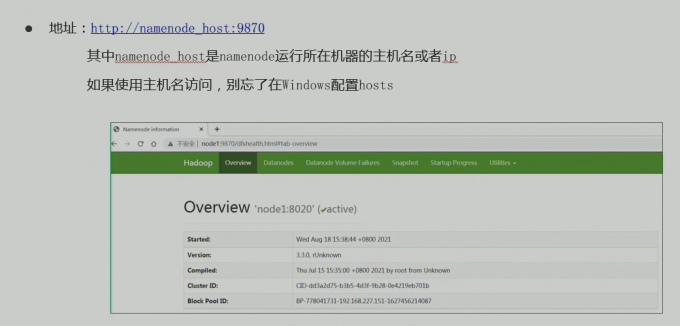
web ui开启
HDFS 集群
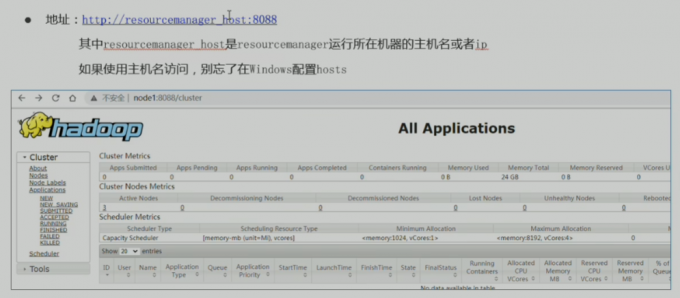
yarn集群
HDFS
- 命令行
1 | # shell 命令操作 |
web ui 操作
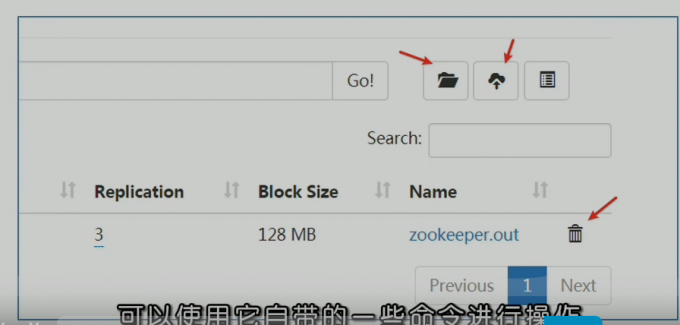
hadoop重要组件-hdfs
HDFS - hadoop分布式文件系统
一个分布式存储系统核心属性
- 分布式存储
- 元数据记录
- 分块存储
- 副本机制(冗余存储)

HDFS 设计场景 是 大文件 大数据场景

- 文件系统协议
1 | HDFS Shell CLI支持操作多种文件系统,包括本地文件系统(file:///)、分布式文件系统 ( hdfs:/nn:8020)等具体操作的是什么文件系统取决于命令中文件路径URL中的前缀协议。 |
- 命令行常用指令
1 | 创建文件夹 |
HDFS 角色划分
- namenode

- datanode

- secondnamenode
namenode的秘书
一般是给namenode分担压力
但是 不能替代namenode
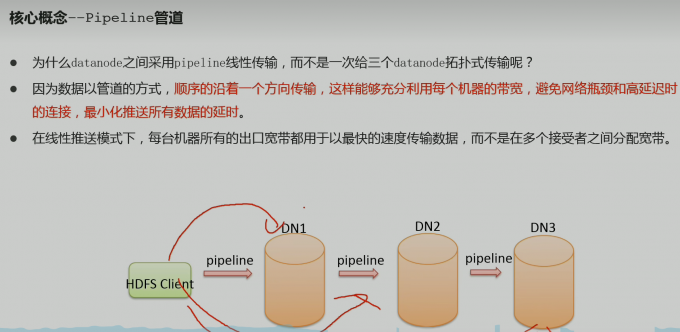
写数据流程
三个核心概念
- pipeline管道
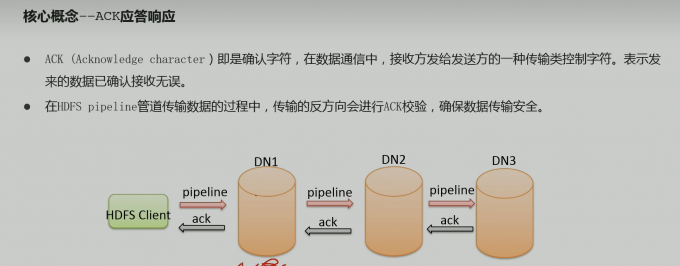
- ack应答响应
- 副本存储

MapReduce
MapReduce-分布式计算框架
MapReduce的思想核心是“先分再合,分而治之”。
所谓“分而治之”就是把一个复杂的问题,按照一定的“分解”方法分为等价的规模较小的若干部分,然后逐个解决,分别找出各部分的结果,然后把各部分的结果组成整个问题的最终结果。
这种思想来源于日常生活与工作时的经验。即使是发布过论文实现分布式计算的谷歌也只是实现了这种思想,而不是自己原创。
- MAP 负责拆分
即把复杂的任务分解为若干个“简单的子任务”来并行处理。可以进行拆分的前提是这些小任务可以并行计算,彼此间几乎没有依赖关系。
- Reduce 负责 合并
对map阶段结果进行全局汇总
在当下 MR框架已经退居二线
- 局限性
实时计算性能差,主要用于离线作业
- 不能进行流式计算
流式计算的特点是数据源源不断得计算,并且数据是动态的
MapReduce 实例进程
MRAppMaster:负责整个MR程序的过程调度及状态协调
MapTask :负责map阶段的整个数据处理流程
ReduceTask:负责reduce阶段的整个数据处理流程
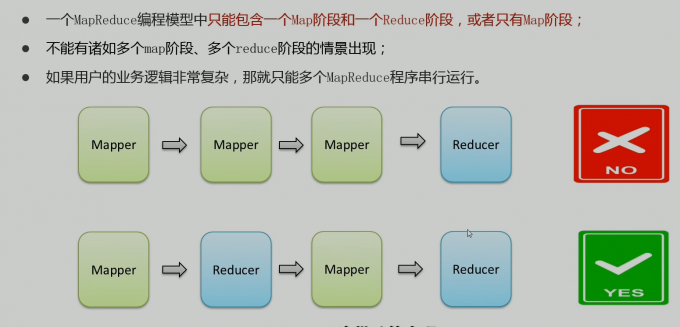
阶段组成
- 一个编程模型中组成
- 1个map 1个reduce
- 只有map
数据类型
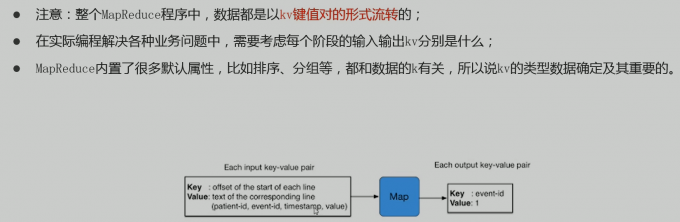
mapreduce 程序运行

map阶段执行过程
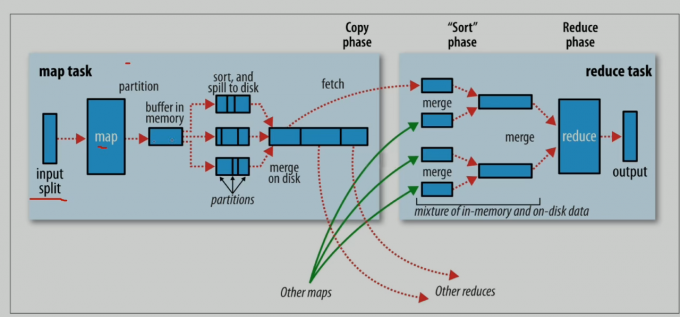


reduce阶段执行过程

shuffle机制
- map端shuffle

- reduce端shuffle

- shuffle机制弊端
- Shuffle是MapReduce程序的核心与精髓,是MapReduce的灵魂所在。
- Shuffle也是MapReduce被诟病最多的地方所在。MapReduce相比较于Spark、Flink计算引擎慢的原因,Shuffle机制有很大的关系。
- Shuffle中频繁涉及到数据在内存、磁盘之间的多次往复。
YARN - 通用资源管理系统和调度平台
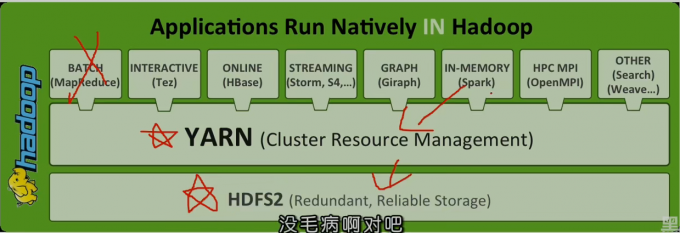
- 资源管理系统:集群的硬件资源,和程序运行相关,比如内存CPU等。
- 调度平台:多个程序同时申请计算资源如何分配,调度的规则(算法)。
- 通用∶不仅仅支持MapReduce程序,理论上支持各种计算程序。YARN不关心你干什么,只关心你要资源,在有的情况下给你,用完之后还我。
- 可以把Hladoop YARN理解为相当于一个分布式的操作系统平台,而MapReduce等计算程序则相当于运行于操作系统之上的应用程序,YARN为这些程序提供运算所需的资源(内存、CPU等)。
- Hadoop能有今天这个地位,YARN可以说是功不可没。因为有了YARN,更多计算框架可以接入到HDFS中,而不单单是MapReduce,正是因为YARN的包容,使得其他计算框架能专注于计算性能的提升。
- HDFS可能不是最优秀的大数据存储系统,但却是应用最广泛的大数据存储系统,YARN功不可没。
YARN 三大组件
- RM(ResourceManager)
YARN集群中的主角色,决定系统中所有应用程序之间资源分配的最终权限,即最终仲裁者。接收用户的作业提交,并通过NM分配、管理各个机器上的计算资源。
- NM (NodeManager)
YARN中的从角色,一台机器上一个,负责管理本机器上的计算资源。根据RM命令,启动Container容器、监视容器的资源使用情况。并且向RM主角色汇报资源使用情况。
- AM (ApplicationMaster ( App Mstr ) )
用户提交的每个应用程序均包含一个AM。应用程序内的“老大”,负责程序内部各阶段的资源申请,监督程序的执行情况。
程序交互流程
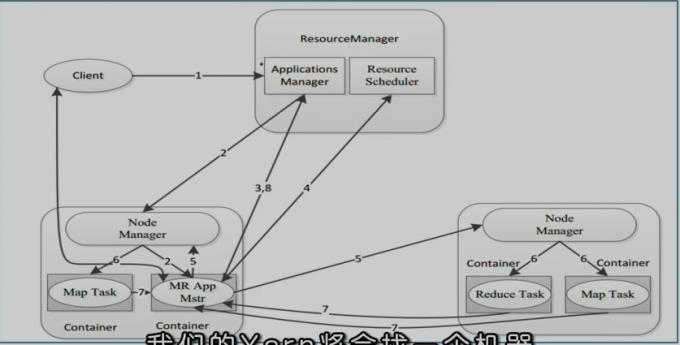
- 核心交互流程
- MR作业提交 Client -> RM
- 资源申请 App Mstr -> RM
- MR 作业状态汇报 Container ( Map|Reduce Task ) –>Container ( MrAppMaster )
- 节点状态汇报 NM -> RM
用户向YARN 提交了一个应用程序后 YARN分两个阶段运行该程序
- 第一个阶段: 客户端申请资源启动本次程序 AM
- 第二个阶段: AM根据本次程序内部具体情况,为它申请资源,并监控它整个运行过程
- 分步讲解
- 用户通过客户端向YARN中ResourceManager提交应用程序(比如hadoop jar提交MR程序);
- ResourceManager为该应用程序分配第一个Container(容器),并与对应的NodeManager通信,要求它在这个Container中启动这个应用程序的ApplicationMaster。
- ApplicationMaster启动成功之后,首先向ResourceManager注册并保持通信,这样用户可以直接通过ResourceManage查看应用程序的运行状态(处理了百分之几);
- AM为本次程序内部的各个Task任务向RM申请资源,并监控它的运行状态;
- 一旦ApplicationMaster 申请到资源后,便与对应的NodeManager通信,要求它启动任务
- NodeManager为任务设置好运行环境后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务
- 各个任务通过某个 RPC 协议向 ApplicationMaster汇报自己的状态和进度,以让 ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC向ApplicationMaster查询应用程序的当前运行状态。
- 应用程序运行完成后,ApplicationMaster向 ResourceManager 注销并关闭自己
scheduler 资源调度器
调度策略