说些废话
目前 论文分析要求 很重 而且 我心很杂 需要一套班子
前言
论文名:SINE Sparse-Interest Network for Sequential Recommendation
链接:
文章介绍链接:(知乎)https://zhuanlan.zhihu.com/p/408714836
相关知识:
- 序列推荐
- 概念原型
- 工业界
1. 相关背景
拟解决的问题:推荐系统的召回阶段仅用一个user embedding无法表征用户丰富的意图。目前通常利用聚类的方法生成多兴趣embedidng的方法,但现实场景的item categories太多 ,聚类不现实。
1)如何有效地利用概念原型对大量的item在细粒度上进行聚类是一项重要的任务。
2)一个人通常只与一组稀疏的概念进行交互,需要准确从全量概念原型中抽出一部分
1.1 核心思想
通过在一个大的核心概念池中 提取对应序列的核心的几个兴趣点
准确从概念原型中抽出一部分对用户意图进行表示
2. 实证分析
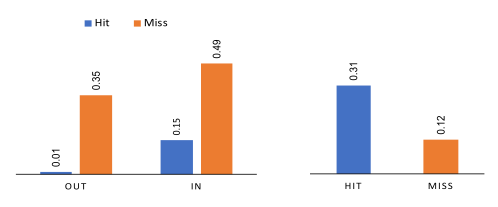
如SASRec仅用单一的emb建模用户丰富的兴趣容易受到recent行为影响
3. 问题描述
序列推荐
4. 方法(基本为论文方法部分)
实验模型
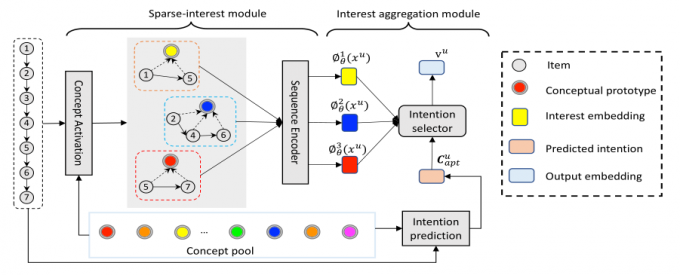
- 稀疏兴趣


多兴趣融合

5. 实验
5.1 消融实验
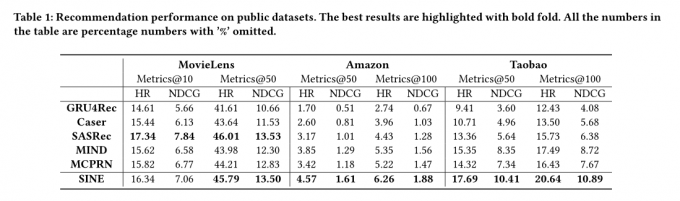
结论:
多头在小数据集结果好
多兴趣嵌入比单兴趣好
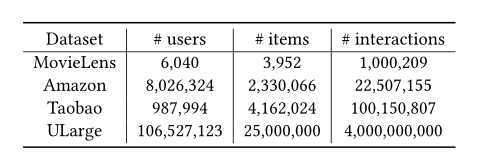
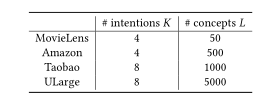
5.2 超参数设计
6. 总结
文章参照显式方法进行的兴趣构建
将SINE与现有方法进行比较,这些方法侧重于在推荐召回阶段提取用户的多兴趣emb。粗略地将它们分为两类,并在下面分析了它们的区别。
隐式方法:这种方法依赖强大的神经网络来隐式聚类历史行为并提取不同的兴趣。例如,MIND [24] 利用 Capsule 网络 [34] 自适应地将用户的行为聚合到兴趣嵌入向量中。 SASRec [21] 采用多头自注意力机制 [43] 为用户输出多个表示。与这些方法相比,我们的模型属于一种显式方法,该方法基于潜在的概念原型从用户的行为序列中显式地检测意图。
显式方法:维护一组概念原型,以明确确定用户行为序列中item的意图。 MCPRN [44] 是最近的一项代表性工作,用于从Session中提取多个兴趣以完成序列推荐。 DisenRec [29] 利用潜在原型来帮助学习用于推荐的解耦表示。与它们相比,文章也遵循显式方法,但SINE可扩展到大规模数据集。具体来说,前人的工作要求不同兴趣emb的数量等于概念原型的数量。然而,潜在概念的数量取决于应用程序,并且在工业推荐系统中可以很容易地扩展到数百甚至数千,这阻碍了它们在实践中的应用。相比之下,SINE能够自动从大型概念池中推断出一组稀疏的首选意图。
7. 自己的想法
现在的我 看过源码 我算是基本没什么想法