说些废话
2022/8/4
在8/2日 在写完core这篇文章的时候 发现 文章的一个思路非常像这篇文中的反事实生成这个部分
还有 我其实写完了sine的文章 但是 学校服务器不让用 就离谱
然后发现 这个东西 我以前度过 说实话 没有整理出来 我东西都忘光了
说实话 现在回头看 自己还是看的不怎么清晰
前言
论文名:CauseRec: Counterfactual User Sequence Synthesis for Sequential Recommendation
链接:
- 论文链接 https://dl.acm.org/doi/abs/10.1145/3404835.3462908
- 代码链接 https://github.com/gzy-rgb/CauseRec
- 文章介绍链接:(知乎)https://zhuanlan.zhihu.com/p/406794449
相关知识:
1. 相关背景
由于记录的用户交互的噪声和稀疏性,仅对观测行为序列进行建模可能最终导致系统脆弱和不稳定。
1.1 核心思想
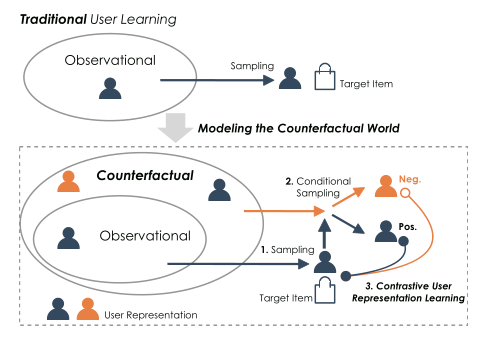
CauseRec通过替换原始概念序列中的可有可无和不可或缺的概念,从反事实数据分布中有条件地采样用户概念序列。利用从合成用户序列获得的用户表示,CauseRec通过对比反事实和观察数据来执行对比用户表示学习。
对比学习
设计了模型无关和非侵入性框架,帮助任何基线模型以端到端的方式学习更有效的用户表示。通过将原始用户表示与反事实正样本和反事实负样本进行对比,这种表示更加准确和稳健反事实建议
专注于去噪用户表示学习,并考虑了回顾问题,即“如果我们干预观察到的行为序列,用户表示会是什么?”。从技术上讲,我们提出了几个基于识别不可或缺/可有可无概念的反事实转换,并设计了几个对比目标,用于学习准确和稳健的用户表示
2. 实证分析
这个实证 是根据作者经验得到
在推荐系统中,用户通常仅与有限数量的项目进行交互,而在大型实时系统中,项目库很容易达到1亿个。因此,仅对既稀疏又有噪声的观测行为序列进行建模可能最终导致不太令人满意的脆弱系统。
3. 问题描述
序列推荐
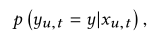
从顺序推荐的观点来看,数据集可以表示为D={(xu,t,yu,t)}u=1,2,…,N,t=1,3,…,Tu,其中xu,t={yu,1:(t−1) }表示用户在第t个行为yu,t之前的历史行为,并按时间顺序排列,Tu表示用户u的行为数。顺序推荐的目标是预测下一个项目yu,t,给定历史行为xu,t,其可以表示为建模所有可能项目的概率
同样的 因为要偶然删除子序列 所以 输入被定成了(关键是 有时候还得提取子序列)
(xu,t,yu,t )
4. 方法(基本为论文方法部分)
注意,文章提出的框架CauseRec的所有变体都是在基础模型上展开的。
4.1 整体架构
模型的本质是 回答追溯问题
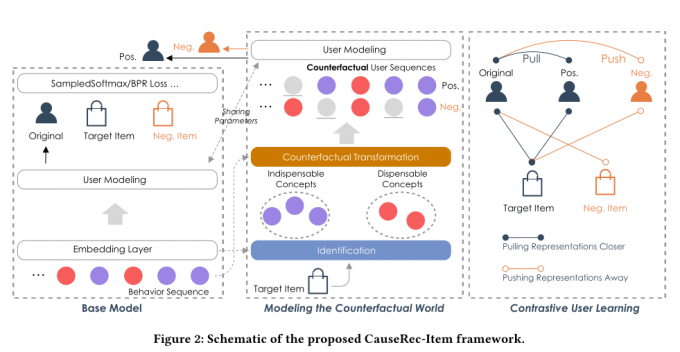
具体来说,我们首先确定历史行为序列中不可或缺的概念。一个不可或缺的概念表示一个行为序列的子集,可以共同表示用户兴趣的一个有意义的方面。可有可无的概念表示在表示感兴趣的方面不太重要的噪声子集
4.2 归纳偏置(类似于先验)
通常情况下,我们不知道具体上帝函数的情况,但我们猜测它类似于一个比较具体的函数。这种基于先验知识对目标模型的判断就是归纳偏置(inductive bias)。归纳偏置所做的事情,是将无限可能的目标函数约束在一个有限的假设类别之中,这样,模型的学习才成为可能。
4.3 概念不可或缺/可有可无的划分
- Item-level Concepts
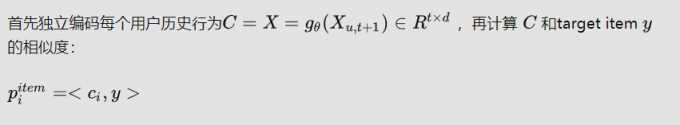
- Interest-level Concepts

反事实变换
旨在通过替换原始用户序列的一部分概念来构建分布外out-of-distribution的用户序列。这里的用户序列可以是众所周知的item序列,也可以是兴趣level的概念序列。基于全局总览中描述的归纳偏差,建议以 rrep 的速率替换已识别的必不可少/可有可无的概念,以分别构建反事实的negative/positive用户序列。直接删除不可或缺/可有可无的概念似乎也是可行的,但替换具有不影响整体序列长度和概念的相对位置的优点。具体来说,文章维护一个先进先出队列作为每个level的概念memory,将从当前mini-batch中提取的全量概念加入队列,并使用dequeue的概念作为替代。(这部分没说清楚可能要看代码)
用户embedding生成

目标函数
除了最大化似然概率的目标函数外,文章引入几个对比学习的目标函数来学习更精确的更鲁棒的用户表示。
反事实和真实序列之间的对比
一个健壮的用户表示应该对序列中可有可无的概念不那么敏感。 因此,从反事实序列中学习到的具有必不可少的概念转换的用户表示应该远离原始用户表示。 类似,准确的表示应该更多地信任不可或缺的概念。 因此,从具有可有可无的概念转换的反事实序列中学习的用户表示应该直观地更接近原始用户表示。因此,文章使用三元组边际损失来衡量样本之间的相对相似性:

不过这里想强调的是,在 测试/服务阶段,生成 user embedding 只用到了原始行为序列,不需要计算 proposal scores 以及 反事实用户序列生成。强调这个原因在于,文章计算 proposal scores 需要用到 target item,而 target item 在测试和服务阶段是看不到的。具体来说,CauseRec-H 和 CauseRec-In 在测试阶段完全一样,而CauseRec-Item 和 Base Model 的差别也是在训练阶段。
5. 实验
验证:1)CauseRec对比SOTA的序列推荐模型性能提升了多少;2)消融实验和超参数对实验指标的影响;3)用户表示如何从反事实数据建模和对比表示学习中受益
效果
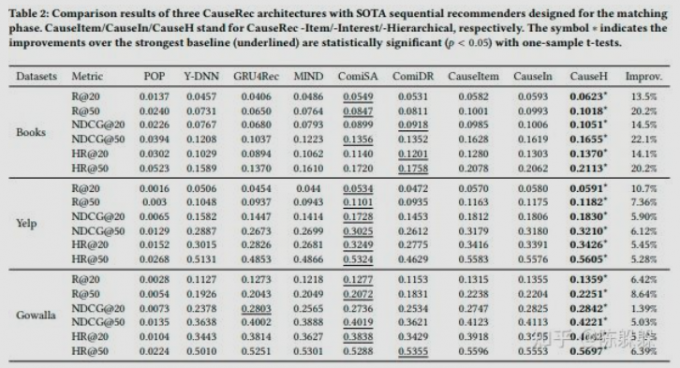
文章验证了 CauseRec 的三种架构,包括 CauseRec-Item (CauseItem)、CauseRec-Interest (CauseIn) 和 CauseRec-Hierarchical (CauseH),观察到这些架构在各种baseline和三个不同指标上的明显改进。值得注意的是,CauseRec-H 对比之前的 SOTA ComiRec-SA/DR 在 Amazon Books 数据集上提高了 +.0299(相对 22.1%)的 NDCG@50 和在关于 Gowalla 上提高了+.0179(相对 8.64%)的 Recall@20。
ComiRec 主要通过对给定用户的多个兴趣进行建模来产生最佳性能。然而,对嘈杂的历史行为进行建模可能会导致可能无法准确代表用户的多样化,最终导致较差的结果。 GRU4Rec 在 Gowalla 数据集上与 ComiRec 取得了相当好的结果。 GRU4Rec 可以有效地对行为序列中item之间的顺序依赖性进行建模。但是,由于严格的逐步编码过程,它可能更容易受到噪声的影响。相比之下,CauseRec 架构通过将用户表示远离反事实的negative的用户表示并将其拉近反事实的positive的用户表示来对抗用户行为中的噪音。此外,这些结果证明了 CauseRec 通过对反事实数据进行建模来应对分布外out-of-distribution的用户序列的泛化能力。
在三种 CauseRec 架构中,CauseRec-Item 是一种模型无关设计,这意味着它可以应用于任何其他顺序推荐系统,而无需对原始用户编码器进行任何修改,并且仅在训练阶段起作用,而不会牺牲推理效率(训练阶段才需要替换掉用户行为序列的一部分,测试阶段完全不需要。)CauseRec-Interest 通过将可能与某一兴趣相关的item(例如巧克力和蛋糕属于糖果)组合成一个整体概念来构建兴趣级别的概念。与 CauseRec-Item 相比,CauseRec-Interest 具有减少概念冗余和建模item之间高阶关系的优点,从而改进 CauseRec-Item。为了结合 CauseRec Interest 和 CauseRec-Item 的优点,CauseRec-Hierarchical 在反事实转换中同时考虑了兴趣级别和item级别的概念。 CauseRec-H 取得了最好的结果,这表明item级概念上的反事实替换仍然产生了一些独特的优势,例如对细粒度偏好进行建模。如人们通常不会喜欢所有的甜食,而更喜欢蛋糕而不是巧克力。(item-level能区分蛋糕还是巧克力,而兴趣level将二者都融合成甜食概念。)
消融实验
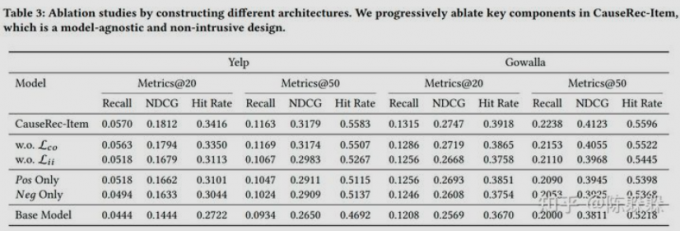
CauseRec-Item 具有以下优点:易于实现(与模型无关)、服务高效(测试阶段不需要做任何的修改)和有效。文章通过消融实验、更好地理解 CauseRec Item 中的不同模块:

6. 总结
文章对反事实数据分布进行建模,以应对推荐系统中的用户交互的稀疏性和噪声行为。文章提出的CauseRec 有条件地对反事实的positive和negative用户序列进行采样,并对可有可无/不可缺少的概念进行转换。文章提出了多种结构(-item、-interest、-hierarchical)来面对细粒度的item-level概念和抽象的兴趣level概念。此外,文章设计了几个对比目标来对比反事实与现实序列数据,以学习准确和鲁棒的用户表示。CauseRec-Item 具有模型无关的优点,即仅在训练中起作用而不影响evaluate/inference效率。大量实验证明 CauseRec 的优势是设计简单且性能有效。
7. 自己的想法
之前没看懂 现在觉得这个工作 很复杂 根本不想看下去
对对对
- 对于 项目的距离是没有一个明细的 (通过替换正负的项目 来实现 是作者的一个先验) 但是 这个操作是不是太过复杂 (理解还好)