说些废话
看到题目
目的解决我的两个疑问
- 什么是一直表示空间
- 简单有效
前言
论文名:CORE: Simple and Effective Session-based Recommendation
within Consistent Representation Space
链接:
- 论文链接 https://arxiv.org/abs/2204.11067
- 代码链接 https://github.com/RUCAIBox/CORE
- 文章介绍链接:(知乎)无
相关知识:
- 会话推荐
- 推荐系统
1. 相关背景
非线性编码器学习的会话嵌入通常与项目嵌入不在同一表示空间中,这导致在推荐项目时出现不一致的预测问题
1.1 核心思想
设计了一种表示一致性编码器,将输入项嵌入的线性组合作为会话嵌入,保证会话和项位于相同的表示空间
使用了一个稳健的距离测量 来使 相近的在一块 其他的偏离
1.2 挑战
- 考虑到会话和项目嵌入共享一致的表示空间,如何设计更合适的编码器,以便我们能够利用深度非线性神经网络的巨大能力
- 一旦表示空间统一,项目嵌入直接涉及分数计算和模型优化,如何测量嵌入之间的距离以避免项目嵌入的过度拟合
2. 实证分析
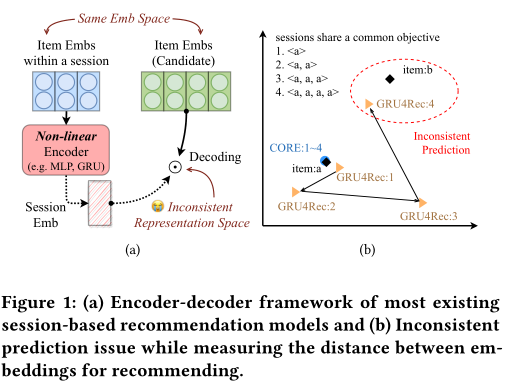
看 实证分析的右侧
匿名用户 点击a 最后 甚至会跑到item b 那里去(离大谱)
事实证明 一致空间 从某种程度来说 也增加了可解释性
3. 问题描述
会话推荐
4. 方法(基本为论文方法部分)
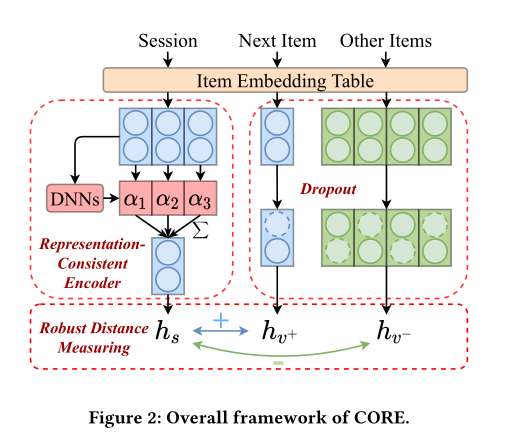
输入 有三
会话
下一个item
其他的item
通过session对话 计算出 每一个session的权重 然后 加和
其训练过程 就是 让 我们 训练出来的一致表示下的item 与 next item 靠经
与 其他地 other item 拉远(这个好好看一下)我看过一篇类似的文章
4.1 DNN
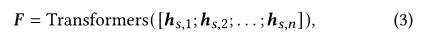
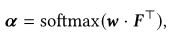
由于会话被编码为项目嵌入的线性组合,并通过测量嵌入空间中到项目的距离来解码,因此项目嵌入直接涉及嵌入之间的距离计算,导致过度拟合的高风险。因此,我们寻求一种稳健的方法来测量统一表示空间中的距离,以防止过度拟合。
说实话 有点看不太懂证明
论文名字:Improved Deep Metric Learning with Multi-class N-pair Loss Objective
看论文 貌似是一个优化方法
本文使用了三种方法来 避免过拟合
使用了一个可控的超参数 来替换 固定裕度2
dropout 很平常
受对比学习启发 使用了 cos 计算测量距离 24
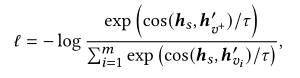
where h′ denotes the item embeddings with dropout.
5. 实验
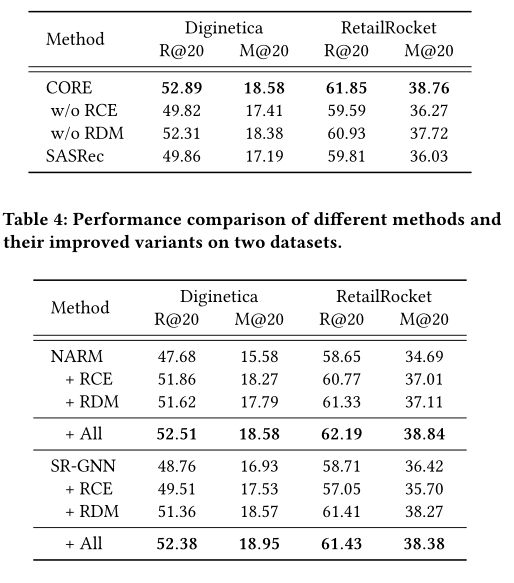
作者做了两个消融实验来证明自己的效果好
将REC编码器(Representation-Consistent Encoding)替换为sasrec编码器
将RDM(Robust Distance Measuring for Decoding)替换成 传统点积
又做了一个添加模块的实验 真不错啊
 ](
](作者 用图来表示空间一致性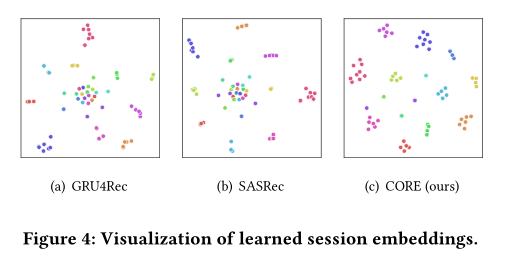
超参数设计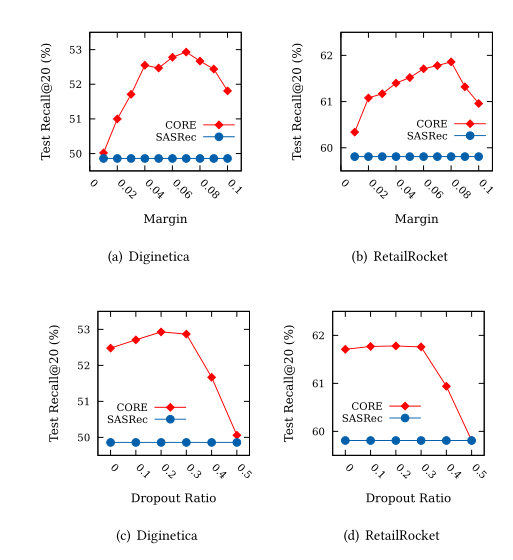
6. 总结
在本文中,我们提出了一种简单有效的一致表示空间中基于会话的推荐框架CORE,该框架在整个编码和解码过程中统一了表示空间,以克服不一致预测问题。与在项目嵌入上堆叠多个非线性层不同,我们建议只对项目嵌入应用加权和,将一致表示空间中的会话编码为项目。此外,我们从多个方面提出了稳健的距离测量技术,以防止所提出框架中项目嵌入的过度拟合。在五个公共数据集上的大量实验表明了所提出方法的有效性和效率,以及所提出的技术如何帮助现有方法。在未来的工作中,我们将考虑从理论和经验两方面研究所提出的表示一致性编码器的表达能力。此外,我们将探讨如何在拟议的框架中引入边特征和有用的归纳偏差
7. 自己的想法
本文的方法简单且有效
对其十分感兴趣的是 一个先有鸡还是先有蛋的问题
即 先想到这个方法 然后跑个实验 给他取了一个漂亮的名字 然后讲了个故事。
还是说 一开始就想到了表示空间一致这个问题 然后 去跑了这个实验 发现有效。
这个真的是个问题。
- sine 中 提取 拉取相近兴趣 拉远 不相关 兴趣 是不是可以思考一下
- 我之前 看到过一篇序列推荐 是 把序列不重要的item替换 然后 做对比学习(其中拉近拉远的操作)就跟这个差不多 我等会去看看