前言
2022/7/29
作为 知识追踪的sota saint+ 前身
主要的作用就是体现出
transformer 变种 在 知识追踪的体现
链接:
论文地址:https://arxiv.org/abs/2002.07033
github: https://github.com/arshadshk/SAINT-pytorch (不太可信)
https://github.com/Shivanandmn/Knowledge-Tracing-SAINT
参考链接:https://zhuanlan.zhihu.com/p/439458114
相关知识:
- Pre-LN https://zhuanlan.zhihu.com/p/480783670
- transformer
1. 相关背景
目前的transformer 模型有两个限制
- transformer 深度不够
- qvk的交互有问题
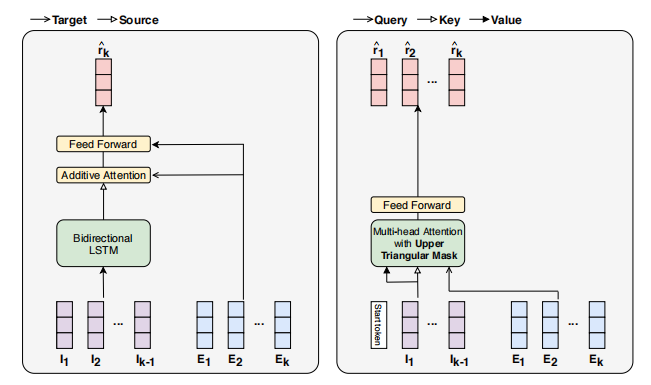
1.1 核心思想
将 运动序列 和 响应序列 分别应用于编码器和解码器
2. 实证分析(有的有 有的没有)
这篇没有分析
3. 问题描述
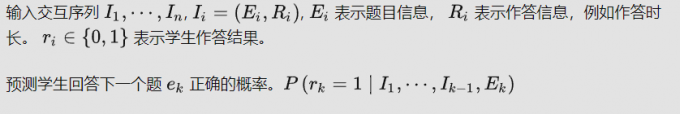
4. 方法(基本为论文方法部分)
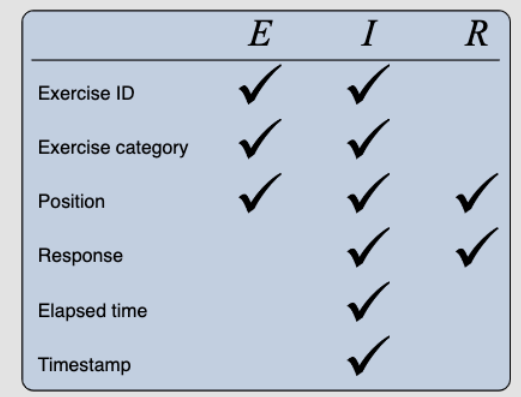
参数使用
练习ID:将潜在向量分配给每个练习唯一的ID
练习类别:每个练习属于领域主题的一个类别。为每个类别分配一个潜在向量
位置:输入序列中练习或响应的位置(第一、第二、…)表示为位置嵌入向量。位置嵌入在运动序列和反应序列中共享
响应:将潜在向量分配给学生响应ri的每个可能值(0或1)
已用时间:学生以秒为单位的响应时间被舍入为整数值。将潜在向量分配给0到300(包括0和300)之间的每个整数。任何超过300秒的时间都被限制为300秒
时间戳:记录学生收到每个练习的绝对时间的月、日和小时。为月、日和小时的每个可能组合分配唯一的潜在向量
论文 使用了三种embedding 作为数据的输入
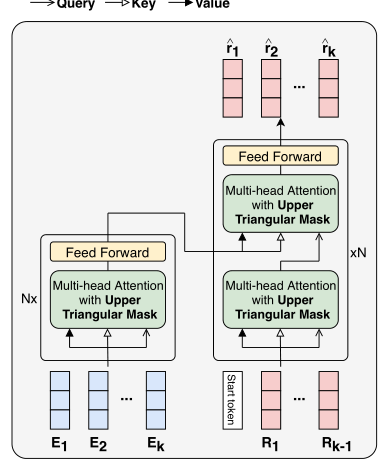
多头
这里使用的是上掩码的权重操作,目的是避免看到未来的信息
Pre-LN
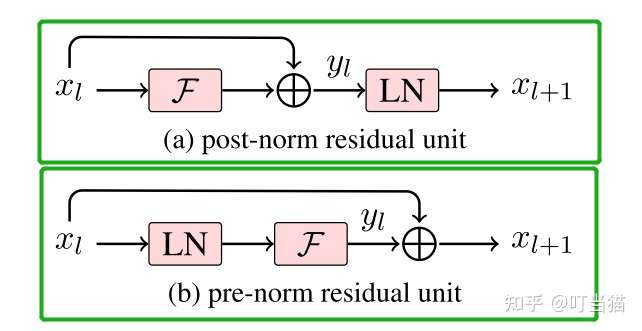
把Transformer架构中传统的Add&Norm做layer normalization的方式叫做Post-LN,并针对Post-LN,模型提出了Pre-LN,即把layer normalization加在残差连接之前
编码器
M = SkipConct(Multihead(LayerNorm(Qin,Kin,Vin)))
O = SkipConct(FFN(LayerNorm(M)))
这里的o 是 encoder 最后的一个输出 在每一层 ln和残差连接都有使用
解码器
M1 = SkipConct(Multihead(LayerNorm(Qin,Kin,Vin)))
M2 = SkipConct(Multihead(LayerNorm(M1,O,O)))
L = SkipConct(FFN(LayerNorm(M2)))
O是编码器的最终输出。译码器中第一层的Qin、Kin和Vin都是Re
我的变体
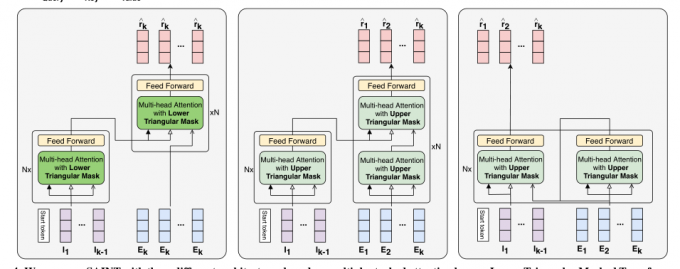
ltmti
区别是
输入解码器序列 变成了 I 不是 e
使用了下掩码 ( 目的是为了让模型关注 most recent (i-1) 来预测。会考虑不同长度的历史信息进行预测,可以当作一种增强 )
UTMTI
UTMTI模型遵循与SAINT相同的架构,仅在输入序列的选择上有所不同。
SSAKT
作者报告,当注意力块被多次叠加时,AUC降低。SSAKT通过在将练习作为查询提供之前在练习上应用自我注意力来解决这个问题。运动自注意力块和运动交互注意力块的输出进入相应的以下块,作为其注意力层的输入
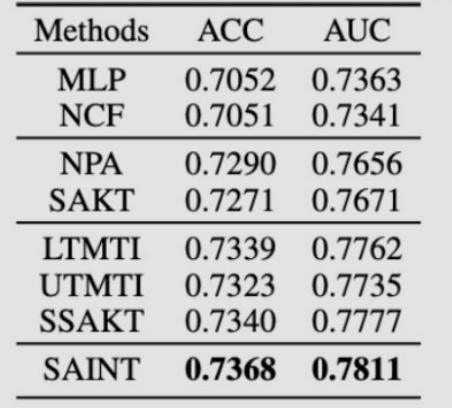
5. 总结
SOTA
6. 自己的想法
在信息的堆叠 不一定能将效果变得更好(UTMTI和saint)
作者堆变体的样子 像是 能发好文章的姿势
可以 像lpkt那种 试着将时间信息加入其中