说些废话
这个文章 是 我在看 知识追踪 的 paperwithcode 时候 偶然 发现一篇文章

前言
论文名:Visual Knowledge Tracing
链接:
- 论文链接 https://arxiv.org/abs/2207.10157
- 代码链接 https://github.com/nkondapa/visualknowledgetracing
- 文章介绍链接:(知乎)https://paperswithcode.com/dataset/visual-knowledge-tracing
- 数据集下载:https://data.caltech.edu/records/20234
相关知识:
- 视觉分类
- 人类类别表示
- 度量学习
- 联合估计
1. 相关背景
人类学习者成功的关键是我们能够从我们周围的世界中提取信息丰富和可概括的表示,以及我们在相对稀疏的反馈下更新这些表示的能力。
其目的是解决三个疑问。
(i)使人类学习的表征如此有效的属性是什么,
(ii)这些表征是如何学习的
(iii)我们可以预测人类在学习过程中的分类行为吗?
最终的目的是了解人类为什么学习如此有效
**我们的目标是估计人类学习者使用的图像分类函数,该函数已提供一系列图像和相应的地面真值类标签作为训练数据 **
1.1 相关工作
- 度量学习: 该工作试图从稀疏的人类注释中学习人类对齐的视觉表示
- 提出了 更具挑战性的视觉知识跟踪设置,其中假设学习者在学习过程中是非平稳的,即他们用于执行手头的分类任务的视觉特征可能会随着时间而变化
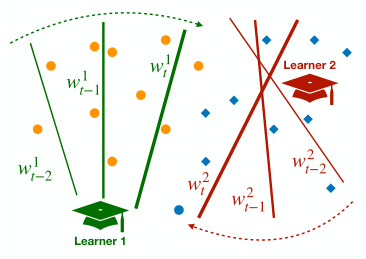
- 提出了一种基于递归神经网络的视觉知识跟踪方法。经过训练后,我们的模型能够预测训练期间未观察到的人类学习者的分类行为。所提出的模型利用以前学习者反应的历史、图像和基本真理类标签来预测他们未来的反应。
度量学习
https://blog.csdn.net/xiaopihaierletian/article/details/53463253
我们可以在特定的任务通过选择合适的特征并手动构建距离函数。然而这种方法会需要很大的人工投入,也可能对数据的改变非常不鲁棒。度量学习作为一个理想的替代,可以根据不同的任务来自主学习出针对某个特定任务的度量距离函数。
如果注释者正在学习感兴趣的视觉概念,则违反了这一假设。在这项工作中,我们解决了这种非平稳设置,并表明通过这样做,我们可以更准确地预测真实人类学习者的视觉分类行为。
人类类别表征
人类会根据任务的不同 使用多种不同的类别学习系统
目前的共识是,根据手头任务的具体性质,人类可能会使用多种不同的类别学习系统[5,3]。例如,在基于规则的任务中,最优策略可能很容易表达,因此可以通过一组规则进行有效编码。然而,在实践中,感知任务(如细粒度视觉分类)可能更难用这种方式表示[8]。
在更具挑战性的环境中,在学习分类任务的过程中,我们的学习者不是静态的。
知识追踪
洒洒水
机器教学
机器教育人类(机器飞升)
机器教学算法通过生成向新手学习者展示的教学示例序列来解决教学问题,以提高他们完成给定任务的能力。
1.2 核心思想
1.3 贡献
(i)一个新的视觉知识跟踪模型,该模型联合估计了非平稳人类学习者使用的视觉特征和每时间步分类函数。
(ii)从参与学习具有挑战性的视觉分类任务的人那里收集的三个基准评估数据集的一组新注释。
(iii)详细比较了这些数据集上的几种视觉知识跟踪方法。
2. 实证分析
没有
3. 问题描述
具体来说,在每个训练时间步,向学习者k呈现图像x,他们提供其响应r,并以正确的类标签y的形式给出反馈。
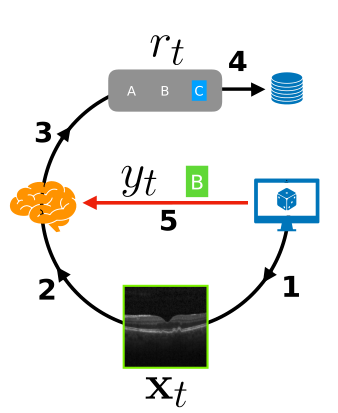
相反,为了克服这种有限的信息设置,我们跨多个学习者训练模型φ,允许该模型发现所有学习者共享的知识状态和学习规则。
4. 方法(基本为论文方法部分)
跟踪模型φ
- 特征提取 f CNN
- 分类函数ψ
- softmax
特点 - 特征提取器在实验的时间间隔内保持不变(针对所有学习者使用相同的底层提取器,且随时间间隔内保持不变) 并且他们只是在对不同视觉特征的相对重要性上有所不同
- 但是 学习者使用的分类函数 不保持静态
分类器
简单静态分类器
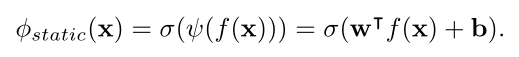
我们探索的第一个模型是最简单的。在这里,我们假设所有学习者使用相同的分类器,该分类器不会随时间变化。在此设置中,ψ是一个多类线性分类器,具有权重矩阵w和每类偏差b
该模型类似于传统的度量学习方法,它不试图捕捉与个体偏差或时间变化相关的任何注释者特定差异。在训练时,我们只需为所有学习者估计一组参数。该模型不考虑响应历史
- 时间敏感追踪模型
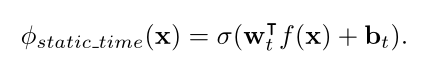 静态跟踪模型的一个明显局限性是,它没有考虑到学习者可能会随着时间的推移而变化的事实,即他们可能在早期的新分类任务中表现得更差,但随着时间的流逝,随着示例图像序列及其相关的基本真理类标签的显示,他们可能会有所改善。一种更先进的模型捕捉到了这种时间演变,即每个时间步长都有不同的分类器,
在每一个时间步,使用不同的偏差和权重 w b i.e. wt 不等于 wt−1.
### 跟踪模型
静态跟踪模型的一个明显局限性是,它没有考虑到学习者可能会随着时间的推移而变化的事实,即他们可能在早期的新分类任务中表现得更差,但随着时间的流逝,随着示例图像序列及其相关的基本真理类标签的显示,他们可能会有所改善。一种更先进的模型捕捉到了这种时间演变,即每个时间步长都有不同的分类器,
在每一个时间步,使用不同的偏差和权重 w b i.e. wt 不等于 wt−1.
### 跟踪模型
以前的问题
即单个学习者可能从不同的能力水平开始,并根据他们所获得的信息以不同的方式更新其内部知识状态。[34]表明,递归网络可用于跟踪参与学习数学测验问题的人类学习者的技能习得。
作者使用了 DKT 作为基础 设计了一个新的基于视觉的DKT模型
直接响应模型
特征提取 CNN
分类函数 lstm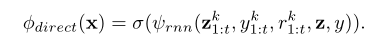
该模型假设学习者在时间t的知识状态由他们之前看到的图像和他们过去的分类响应定义。递归模型可以通过调节学习者的隐藏状态为其生成独特的转换。在这种情况下,在共享特征提取器将图像转换为特征向量后,模型根据学习者的隐藏状态通过一系列非线性变换修改特征向量。最后一个线性层将特征向量转换为预测响应。注意,该模型还以当前查询图像z=f(x)和相应的真值类标签y为条件
分类器预测模型
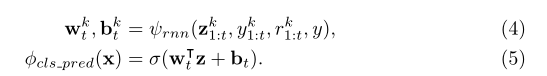
与之前的直接预测递归模型不同,我们现在明确表示单个学习者使用的独立的分类函数。
5. 总结
在这项工作中,我们探索了视觉知识跟踪的问题,即预测人类学习者使用的内部、可能随时间变化的图像分类功能的任务。为此,我们提出了一系列复杂度从基本静态线性分类器到递归模型的模型,这些模型在预测学习者未来行为时考虑了学习者先前的反应历史。我们从参与视觉学习任务的人那里收集了三个具有挑战性的视觉分类任务的新注释,以便对这些不同模型的性能进行基准测试。
6. 自己的想法
- 找出开放性问题
- 知识追踪来说 有个学习的权重分配。相近的权重相对较高,离的较远的权重分配的较低
- 这个是一个特别新的工作 论文出来估计才两个星期 需要好好阅读