看的是 李沐的视频
https://www.bilibili.com/video/BV1FM4y1c7yG
https://www.bilibili.com/video/BV1vQ4y1e7LF
前言
- 开始一个好的基线
- 改一个值 重新训练模型
- 重复很多次 去获得直觉
什么超参数很重要
模型对于超参数 的敏感程度(Adam比SGD 调参要简单很多)
超参数的范围在哪里 结果会好
做好笔记
- 需要认真的管理 (训练日志和超参数)execl 或着 word tensorboardweight&bias
- 重现很难(硬件,库,代码,随机性)
自动调参
- HPO 超参数优化 更加泛化一点
- NAS HPO的小一点版本 专注于神经网络

HPO 哈哈哈
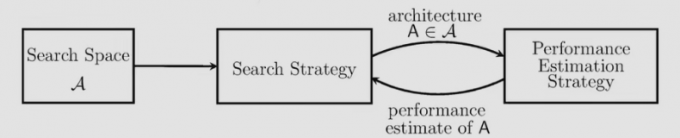
搜索空间

算法1 黑盒算法
遍历! 找到最好的 也是最傻的算法
算法2 多准确度(加速)
目前再用的算法
- 小数据集
- 缩小模型规模 层 通道数
- 快点停止
搜索策略(黑盒子)
第一个暴力穷举(贵)
第二个随机取(有效) 写代码很简单
第三个 贝叶斯 (李沐说这个大研究方向 咱不研究 咱不用)

搜索策略 (多准确度)深度学习较多
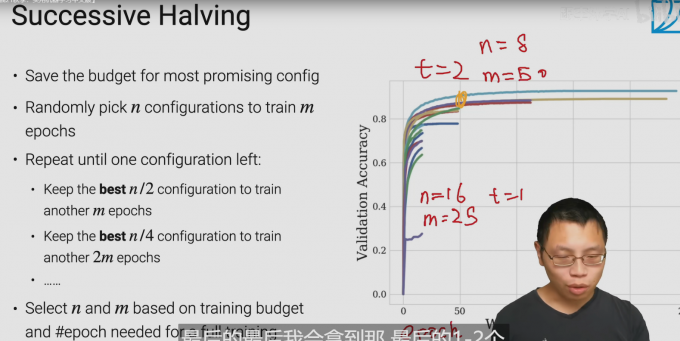
sh算法
- 节省花销对于多超参数
- 随机选取n个参数 去训练m个epoch
算法过程
- 类似一种 递归的思想在其中
- 选取n/2的超参数进行训练 训练m次epoch
- 选取n/4的超参数训练 训练2m次epoch
m n 的选取 取决于 你的预算花销
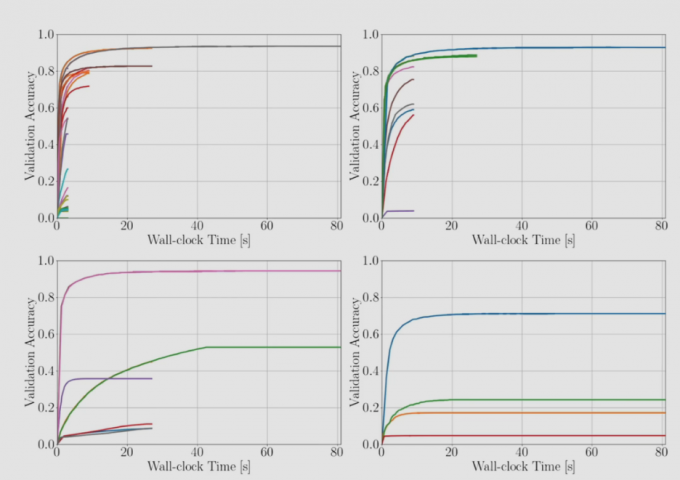
hyperband 用的较多
多跑几个sh算法
在每次跑完后
减小n 增大m
每次都是用不同的m 和 n
影响是 对于 m n的选取 没那么大的影响
Neural Architecture Search (NAS)神经结构搜索
这里只关心 神经网络的参数
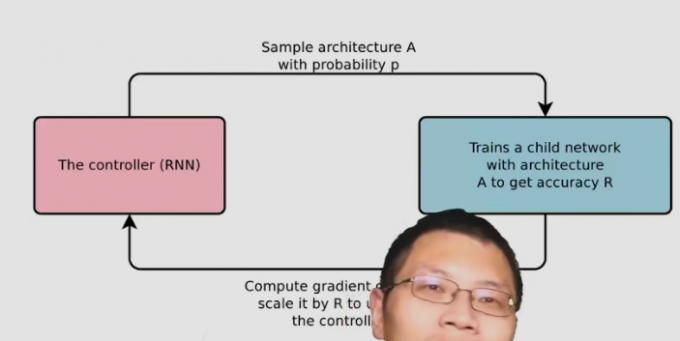
强化学习 nas
代价非常贵
模型优美
one-shot方法
学习模型架构 外加超参数
因为 这个东西看起来就很大
所以 关注点在于
- 只关心架构之间的排名关系
- 用一个近似的指标 : 只训练很少的epoch 来验证
one-shot方法 – 可微架构搜索
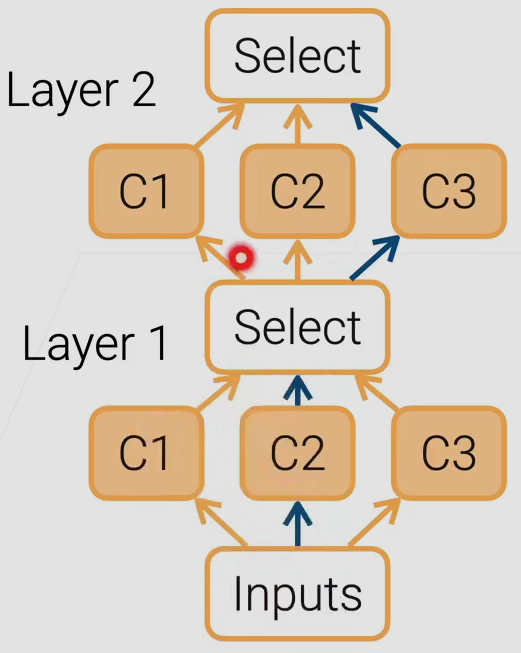
- 多种候选层方法 在每一层
- 在layer层 中 所有的候选层方法 都会有个输出
- 对于这个输出 添加一个大于0 且 相加为1 的权重系数相乘
- 最后 学习 得到 在候选层 中权重最大的给保留下来
通过学习 来判断最好的那一条路径
使用DARTS 这个方法 可以在三个GPU天 完成sota效果
简单实用 effientNet
调参不多 cnn优化
更多层
更多输出通道
输入图像更大

目前研究方向
- 可解释性
- 调整参数 能使用在边缘设备都能跑
- 整个流程更加的自动化