这是16年出的一篇基于session时序建模的召回模型paper,在当时大部分模型只考虑用户最后点击行为,而忽略用户历史点击行为。虽然用户最后一次点击行为与用户下一次点击的item相关度很高,但是用户历史点击行为一方面丰富了用户画像,另一方面用户的兴趣是多峰的,不一定最后一次点击是最相关的。
模型到现在看的话 实在是简单了一些
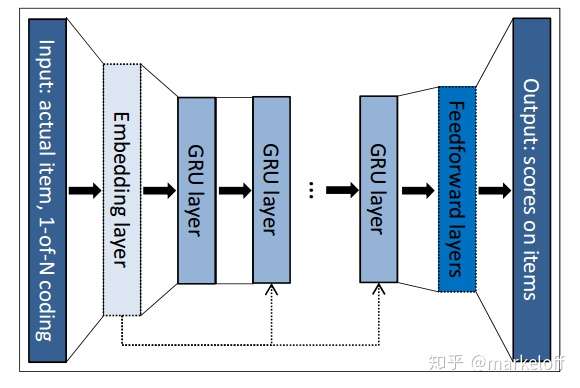
重要的是得看他的亮点
1. 亮点
说实话 第一个两点我看了半天(可能是上午的吃的太少 抑或是 钱给的太少)
1.1 亮点1 训练时session重组

好笑的是 我怎么忘了这个东西
本文的训练过程是 通过i1,1 来预测 i1.2
所以训练序列要比 会话序列 要短一个
假设一个batch有三条数据,代表不同的session。大家看到session1有4条数据,session2有3条数据,session3有6条,真正作为input的话,每个session中item序列长度只有3,2,5,next item是作为groud truth。记录下batch最短的input 长度为2。首先组装 作为第一个batch的input,output是
,然后组装第二个batch,input:
,output:
,这时候session2已经处理完了,但是session1,session2还没有处理完,这时候用session4来替换session2,切换session的时候要重新初始化下hidden state。这时候第三个batch的input变成了
,output是
。到第四个batch的时候session1也处理完了,使用session5来替换。这样下来就能支持多个session并行处理,极大的提升了训练速度。
注意
为了保证Session内的连续性和Session间的独立性:

1.2 亮点2 negative sampling
作者解释这种负采样方法,首先提出了一个假设,那就是用户不太可能将没见过的东西标记为负样本。如果一个物品很流行,而用户却没有在next-item位置进行点击,那么用户大概率在该时序点不喜欢这个物品。
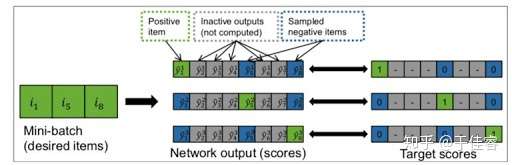
基于这样的假设和观察,作者认为,应该基于物品的流行程度进行负采样,那么作者就提出了一个巧妙的快速负采样方法,那就是一个batch中的其他序列的next-item作为负样本。如下图: 序列的next-item的gt是1, 5, 8对于1来讲 5,8是负样本。和随机抽样相比,个人觉得优势有两个: 一个是基于pop的采样,可解释性更强,另一个是对于batch内需要计算的item是一致的,那么可以将batch内所有序列的next-item预测,统一成一个矩阵运算,大大降低显存占用
同一个batch 时序 其他的mini-batch 为负样本 表示 用户在这个时间内 不喜欢该样本
2. 作者的发现
- 多layer不一定好
- one-hot的编码更好
- 每一步输入前面所有的信息和前一步信息性能差不多
- 提高GRU的宽度有帮助
作者的发现表明 GRU 足够可以编码 item 信息(one-hot更好),单个layer就可以达到很好的效果,对序列的建模能力比较好。