0. 前言
这篇文章想写好久了,一直拖着。其一开始 在阅读 SASrec的时候 发现为了加入注意力机制 给了三个处理过拟合的方法 为此 想写一个文章 来整理一下 这三个技术的作用
1. dropout
感谢:https://blog.csdn.net/program_developer/article/details/80737724
1.1 出现的原因
在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象。在训练神经网络的时候经常会遇到过拟合的问题,过拟合具体表现在:模型在训练数据上损失函数较小,预测准确率较高;但是在测试数据上损失函数比较大,预测准确率较低。
过拟合是很多机器学习的通病。如果模型过拟合,那么得到的模型几乎不能用。为了解决过拟合问题,一般会采用模型集成的方法,即训练多个模型进行组合。此时,训练模型费时就成为一个很大的问题,不仅训练多个模型费时,测试多个模型也是很费时。
综上所述,训练深度神经网络的时候,总是会遇到两大缺点:
(1)容易过拟合
(2)费时
Dropout可以比较有效的缓解过拟合的发生,在一定程度上达到正则化的效果。
1.2 啥是dropout
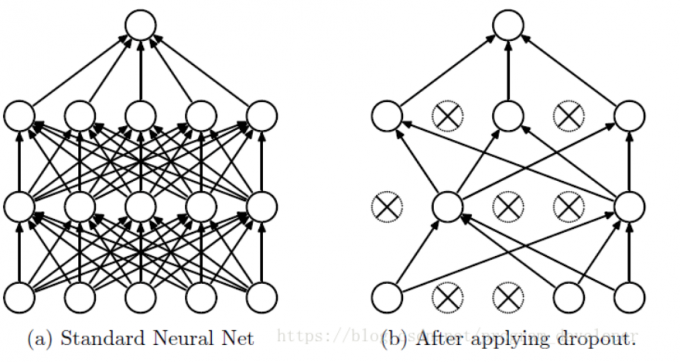
Dropout可以作为训练深度神经网络的一种trick供选择。在每个训练批次中,通过忽略一半的特征检测器(让一半的隐层节点值为0),可以明显地减少过拟合现象。这种方式可以减少特征检测器(隐层节点)间的相互作用,检测器相互作用是指某些检测器依赖其他检测器才能发挥作用。
Dropout说的简单一点就是:我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征
1.3 why?
(1)取平均的作用: 先回到标准的模型即没有dropout,我们用相同的训练数据去训练5个不同的神经网络,一般会得到5个不同的结果,此时我们可以采用 “5个结果取均值”或者“多数取胜的投票策略”去决定最终结果。例如3个网络判断结果为数字9,那么很有可能真正的结果就是数字9,其它两个网络给出了错误结果。这种“综合起来取平均”的策略通常可以有效防止过拟合问题。因为不同的网络可能产生不同的过拟合,取平均则有可能让一些“相反的”拟合互相抵消。dropout掉不同的隐藏神经元就类似在训练不同的网络,随机删掉一半隐藏神经元导致网络结构已经不同,整个dropout过程就相当于对很多个不同的神经网络取平均。而不同的网络产生不同的过拟合,一些互为“反向”的拟合相互抵消就可以达到整体上减少过拟合。
(2)减少神经元之间复杂的共适应关系: 因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况 。迫使网络去学习更加鲁棒的特征 ,这些特征在其它的神经元的随机子集中也存在。换句话说假如我们的神经网络是在做出某种预测,它不应该对一些特定的线索片段太过敏感,即使丢失特定的线索,它也应该可以从众多其它线索中学习一些共同的特征。从这个角度看dropout就有点像L1,L2正则,减少权重使得网络对丢失特定神经元连接的鲁棒性提高。
(3)Dropout类似于性别在生物进化中的角色:物种为了生存往往会倾向于适应这种环境,环境突变则会导致物种难以做出及时反应,性别的出现可以繁衍出适应新环境的变种,有效的阻止过拟合,即避免环境改变时物种可能面临的灭绝
2. 残差网络(Residual Network),残差连接(skip-connect)
感谢:https://blog.csdn.net/weixin_43135178/article/details/115447031
2.1 动机
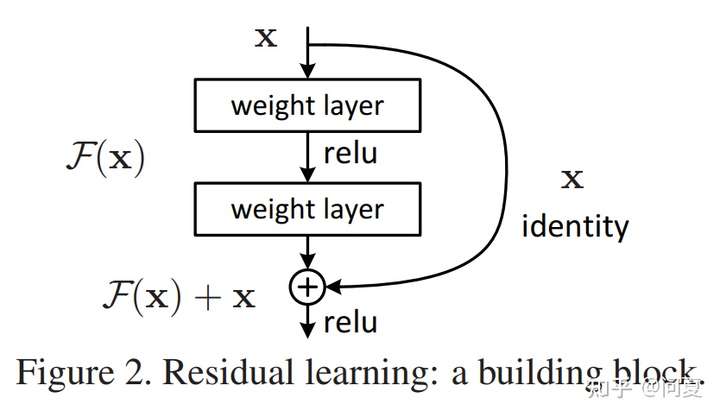
深度神经网络的退化问题 以及 梯度弥散/爆炸 问题
残差网络很好地解决了深度神经网络的退化问题,并在ImageNet和CIFAR-10等图像任务上取得了非常好的结果,同等层数的前提下残差网络也收敛得更快。这使得前馈神经网络可以采用更深的设计。除此之外,去除个别神经网络层,残差网络的表现不会受到显著影响
3. 归一化
https://zhuanlan.zhihu.com/p/432176139 BN 和 LN区别
https://zhuanlan.zhihu.com/p/113233908 还是区别
https://zhuanlan.zhihu.com/p/311165133 这个应该是最能让人清楚的bn 和 ln 区别的文章
https://zhuanlan.zhihu.com/p/74476637 归一化的整体理解
https://blog.csdn.net/weixin_43687366/article/details/108572992 norm pytorch 怎么用
3.1 作用
Norm起作用的本质是它平滑了Loss,保持了梯度下降过程中的稳定。
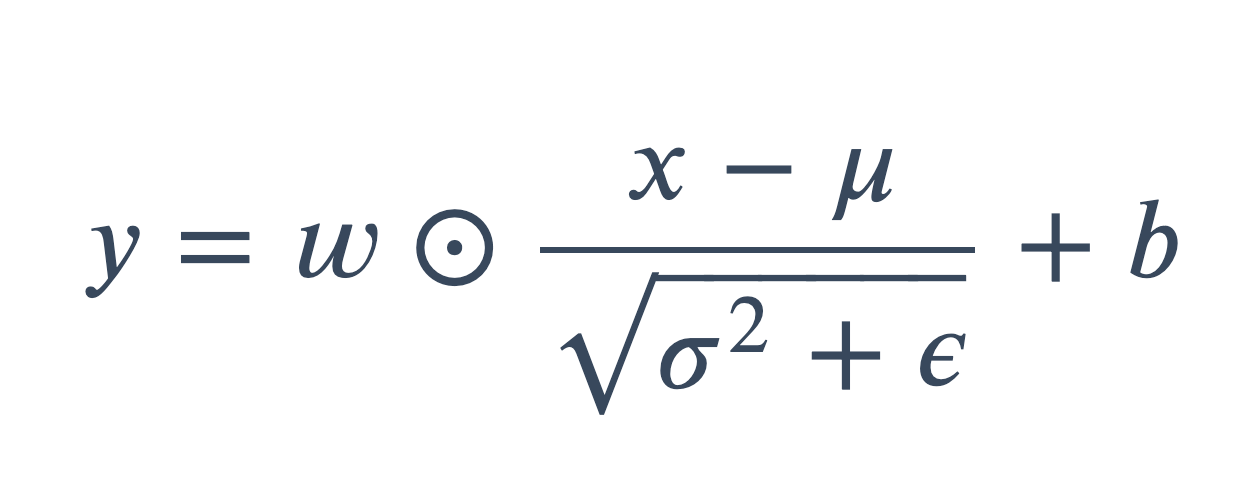
3.2 layer normalization
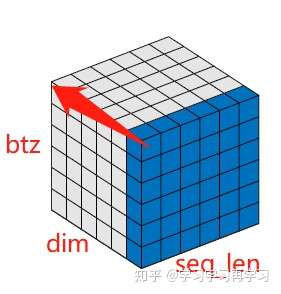
Latch Normalizaiton在NLP中的直观图中,是对一个btz中的同一句话中每个字进行归一化,即图中红色箭头方向,对该方向这一桶计算均值和方差后,计算归一化;以此对整个btz进行归一化。
3.3 Batch Normalizaiton
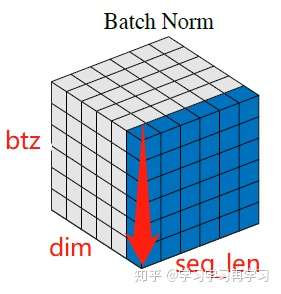
Batch normalizaiton在NLP中的直观图中,是对一个btz中的每句话同一个位置的字进行归一化,即图中红色箭头方向,对这一桶计算均值和方差后,计算归一化;以此对整个btz进行归一化。
BN缺点
* Btz太小会影响。对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布;
* BN实际使用时需要计算并且保存某一层神经网络batch的均值和方差等统计信息,对于对一个固定深度的前向神经网络(DNN,CNN)使用BN,很方便;但对于RNN来说,sequence的长度是不一致的,换句话说RNN的深度不是固定的,不同的time-step需要保存不同的statics特征,可能存在一个特殊sequence比其他sequence长很多,这样training时,计算很麻烦
BN不适用于RNN等动态网络,适用于CNN;LN适用于RNN。