2022年5月1日21点20分

先放一张图片 high! 一下
在这里终于能理解到 为什么pytorch 的好用
和我对embedding 操作 将近一个月的误解!!
我真的是high到不行了
0. 前言 (很重要)
对于一位5月1号 在看着风骚律师 在看着一个名字叫做caser推荐论文的同学。这里面论文里面的一句话,深刻的激发了我。即 俺终于知道如何编码序列推荐数据了!
其实 在这里面最主要的一个体会是!
勇敢 即 主动迈出那一步!!
说太多了
先看看论文里面的那句话!

这里的set和universe 用的太美了 brilliant!
下面这句话非常重要
用户的交互序列其实就是一个物品序列的组合!!!
1. 自己以前的误解
1.1 误解1
本人一直以为 embedding 一定得是one-hot 转换成 embedding-vector
即 我认为简单数字是不能embedding的
大错特错!!!
数字为什么就不能表示物品的特征呢!
数字为什么就不能表示物品的特征呢!
数字为什么就不能表示物品的特征呢!
数字 简单,那么可爱 就应该被embedding
我觉得我这里的误解 应该是犯了教条主义的错误!!!
哈哈哈
1.2 误解2
即 我认为的交互序列是存在点击和不点击这样子的其他属性的
正好最近阅读了 知识追踪 反而没起到正作用 反而放这个让我的误解加深了!
论文里面的一句话!
用户序列 中的元素 即为物品序列的子元素
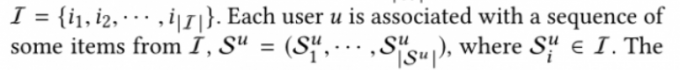
1.3 误解3
我觉得这里 应该是犯了 实践-理论-实践 这个基本道路的错误
为什么 你在没有实践后 就贸然的翻阅理论呢!
可笑!!
我这一周 基本一直在思考 如何找人家 是如何讲数据集 处理成 序列推荐 模型的数据
然后 一直在抱怨 为什么 我的数据集 相对 cv 的 数据 是多难处理
最后 在读caser 这篇文章的时候 才发现自己是多么的沙雕!
本来就是一句话的事情 自己想的太复杂了

- 心得1
多看论文 说不定有个人能说的很明白 一句话的事儿
- 心得2
多实践 只有多试试 才能 发现找到新的道路
2. 上代码
1 | # 老家伙 |
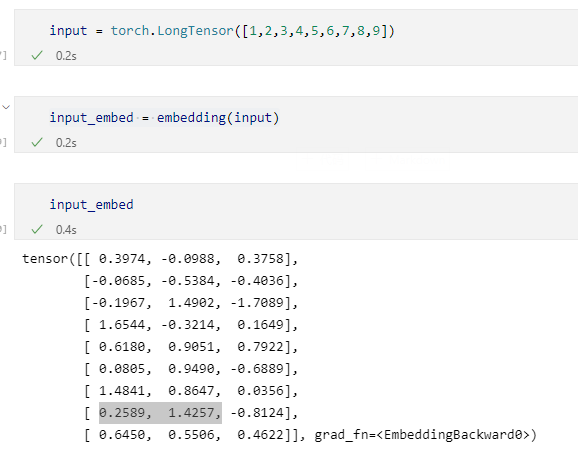
1 | input = torch.LongTensor([1,2,3,4,5,6,7,8,9]) |
1 | ## 真的有趣的部分 |
观察两个output
其 元素是对应的
其元素是对应的
对应的
好的 我说完了!