0. 前言
感谢:
https://www.jianshu.com/p/b4128bc79df0
https://zhuanlan.zhihu.com/p/371849616
https://zhuanlan.zhihu.com/p/57162373
https://zhuanlan.zhihu.com/p/193101514
在主流的FM与DNN的结合方法中,这个明显是并行的结构
大家晓得xdeepFM 这个东西嘛 这个东西与deepFM 的区别是 根本没有什么相似性
不信 看看网络结构图
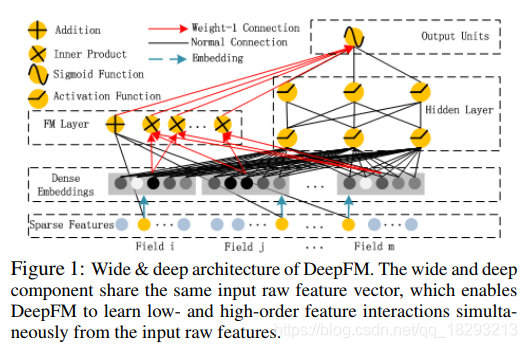
- 这个是deepFM
- 这个是大名鼎鼎的xdeepFM
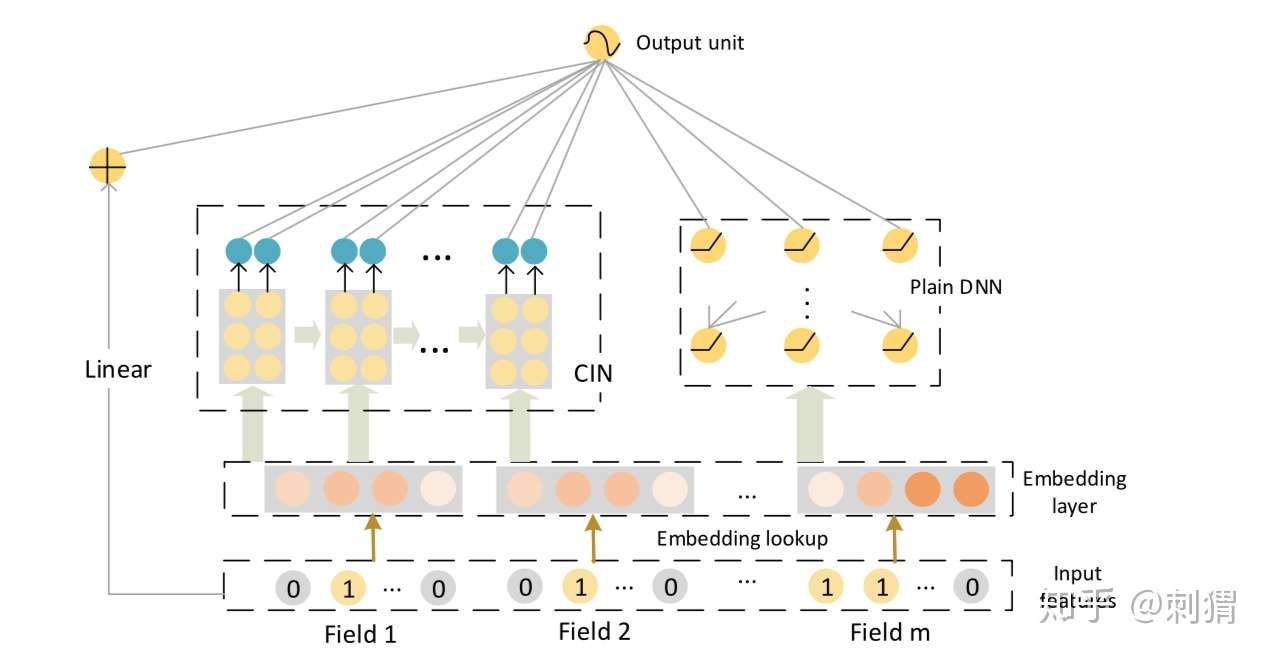
个人的瞎吉儿理解:在结构上,这两个玩意如果实在工程使用上 我肯定会选择deepFM。xdeepFM在网络结构上就存在这一些复杂性,在deepFM的基础上增加了linear层和cin这个不晓得是啥的玩意。在理解中 这个应该是我们xdeepFM 想要替换在deepFM 中 FM的部分
1. 模型的结构难点和自己的思考
既然说这个模型我都看了两天 自然有其难点的地方 cin 的操作啊 还有其为什么强的地方
1.1 难以理解的cin
讲明白一个东西首先先讲明输入输出
输入:field后的embedding层向量
输出:sum pooling后concat一个向量
1.2 介绍角色
说明啊
m 是 filed的个数
D 为 embedd维度
Hk 为第k层特征向量的数量
Xk 为第k层的隐向量
冤大头
首先说明白冤大头的样子
| embedd 1 |
|---|
| embedd 2 |
| ******** |
| embedd m |
这个东西会反复使用(的确是冤大头)
假如说 我有一个这样的隐藏层 我这边感觉第一个隐藏层肯定是随机生成的
其与冤大头 拥有一个相同长度的D边 与隐藏层进行外积操作
于是可以得到一个 长方形的过渡张量
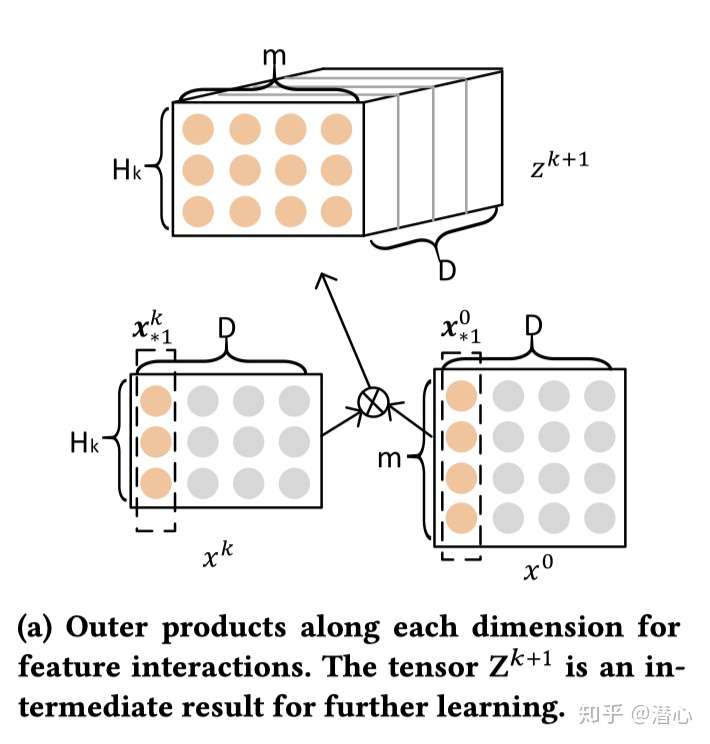
其作用是求出下一个隐藏层
1.3 下一个隐藏层求法
本人将用最简单的话来说明白下一个图的意思
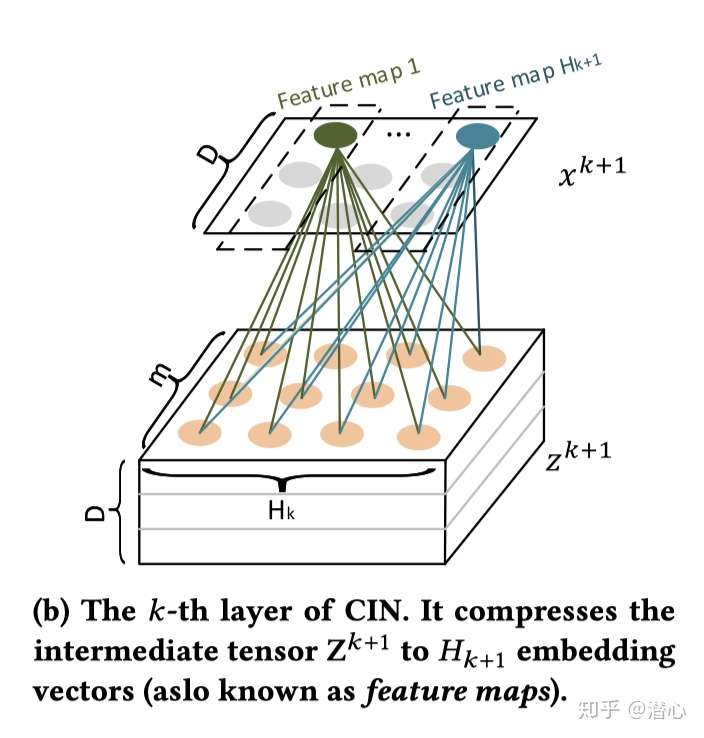
欧克 图里面最直接就能看到一个躺着的张量 ,上面能看到,一个平铺的向量
其宽为D 长度为Hk+1
先从最基础的绿色的点开始
- 每一层都会得到一个绿色的点,张量的高为D 所以得到隐向量的宽为D
- 隐向量的长度为Hk+1,这个数据的设置 没有任何根据 属于随心所欲
- 绿色点的计算 会使用到一整个面的橙色的点
1.4 张量的生成
我们获得了 隐向量
将其与 冤大头做外积 既可以获得下一层的过渡张量
然后 根据1.3的做法 生成对应的隐藏层
1.5 (1.3,1.4)循环
噢噢噢噢 终于有k个隐藏层了呢
1.6 汇总
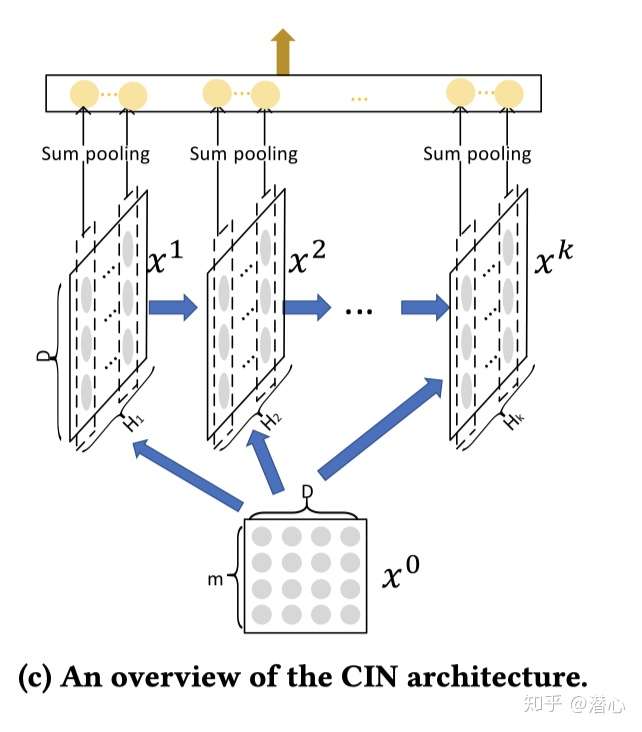
每个隐藏层为,对于第
层,将所有的特征映射进行一个池化操作(sum pooling)【例如对上图Feature map 1向量进行一个累加】:
因此便得到一个池化向量对于第
隐藏层。
最后在对于所有的隐藏层的池化向量进行一个拼接:
2. cin的性能
- 空间复杂度
主要的学习参数就是,经过上述分析,第
层的共有
个参数。假设包括CIN经过一个二元分类任务,那么CIN总共的学习参数为
- 时间复杂度
计算的时间复杂度为
,那么对于
层CIN的总时间复杂度为
- 优点
(1)交互是向量的交互,不是位(元素)级别(bit-wise)的交互; (2)高阶特征交互是显示的; (3)网络的复杂性不会随着交互程度的增加而呈指数增长;
3. 个人的理解
对于xDeepFM模型,我们假设CIN的深度与特征映射的数量都为1,则「xDeepFM就相当于DeepFM的一个泛化」。当进一步删除DNN部分,并且对于特征映射使用一个sum filter,那xDeepFM就将为一个传统的FM模型。【联想之前的分解】