在反复回卷的attention中,本人感觉心里憔悴
一定得总结一个俺能看懂的文章 最近发现了这样的一篇
感谢:
https://zhuanlan.zhihu.com/p/77307258
https://jalammar.github.io/illustrated-transformer/
https://zhuanlan.zhihu.com/p/91839581
阿里妹导读:曾被 paper 中各种各样的 Attention 搞得晕晕乎乎,尽管零零散散地整理过一些关于Attention 的笔记,重点和线索依然比较凌乱。今天,阿里巴巴工程师楠易,将 Attention 的知识系统性地梳理、回顾、总结,不求深刻,但求浅显,希望能帮助对 Attention 有疑惑的同学。
0. 什么是attention
Attention(注意力)机制如果浅层的理解,跟他的名字非常匹配。他的核心逻辑就是「从关注全部到关注重点」
1. attention 分类
涉及所有的 attention 都继承于这个抽象类。这里我写了两个抽象类,一个叫 alignment-based,一个叫 memroy-based。
1.1 alignment-based 模型

c 为 context y1 y2 —–yn 为输入 input 输出为z
1.2 拆分 attention model
分为三部曲
- score function :度量环境变量与当前输入向量的相似性;在当前环境下,应该关注哪些信息

- alignment function:计算attention weight (权重) 通常使用softmax进行归一化
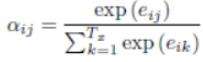
- generate context vector function : 根据 attention weight 得到输出向量

在整体视角下,就像下图这个样子:

1.3 memory-based 模型 长得很像transformer

另一种视角是 QKV模型,假设输入为 q,Memory 中以(k,v)形式存储需要的上下文。感觉在 Q&A 任务中,这种设置比较合理,transformer 是采用的这种建模方式。k 是 question,v 是 answer,q 是新来的 question,看看历史 memory 中 q 和哪个 k 更相似,然后依葫芦画瓢,根据相似 k 对应的 v,合成当前 question 的 answer
1.4 建模方式
三步
- address memory (score function): 在memory找相似的东西

- normalize(alignment function) :

- read content( gen context vector function ):

2. attention 细节
在attention机制中,其建模方式主要就是以下的三类 按人话说
- 找相关 度量环境向量与当前输入向量的相似性;找到当前环境下,应该 focus 哪些输入信息( score-function )
- 算权重 计算 attention weight,通常都使用 softmax 进行归一化 ( alignment function )
- 出结果 根据 attention weight 得到输出向量 ( generate context vector function )
2.1 score function 的区别
score function 在本质上是度量两个向量的相似度。找出相关的部分
- 两个向量在一个空间
使用 dot 点乘方式(或者 scaled dot product,scaled 背后的原因是为了减小数值,softmax 的梯度大一些,学得更快一些),简单好使。
- 不在同一个空间
需要一些变换(在一个空间也可以变换),additive 对输入分别进行线性变换后然后相加,multiplicative 是直接通过矩阵乘法来变换
2.2 alignment function 区别
在 soft attention 中,又划分了 global/local attention 。
global attention 是所有输入向量作为加权集合,使用 softmax 作为 alignment function,local 是部分输入向量才能进入这个池子。
- local的目的
背后逻辑是要减小噪音,进一步缩小重点关注区域。
- 如何缩小关注区域
local-m 基于的假设生硬简单,就直接 pass了。local-p 有一个预估操作,预计当前时刻应该关注输入序列(总长度为S)的什么位置 pt(引入了两个参数向量,vp,wp),然后在 alignment function 中做了一点儿调整,在 softmax 算出来的attention wieght 的基础上,加了一个以 pt 为中心的高斯分布来调整 alignment 的结果。
在应用中 发现 从global/local 视角的分类来看,更常用的依然还是 global attention,因为复杂化的local attention 带来的效果增益感觉并不大
2.3 generate context vector function
soft/hard attention
最直观的一种理解是,hard attention 是一个随机采样,采样集合是输入向量的集合,采样的概率分布是alignment function 产出的 attention weight。因此,hard attention 的输出是某一个特定的输入向量。soft attention 是一个带权求和的过程,求和集合是输入向量的集合,对应权重是 alignment function 产出的 attention weight。hard / soft attention 中,soft attention 是更常用的(后文提及的所有 attention 都在这个范畴),因为它可导,可直接嵌入到模型中进行训练,hard attention 文中 suggests a Monte Carlo based sampling approximation of gradient。