之前 写过一篇 太烂了 在重新写一篇生动的
数据预处理与特征工程:https://blog.csdn.net/qq_37334135/article/details/86825190
目前项目涉及三个数据集(criteo,amazon,movielen)
其中 criteo数据集肯定是使用的最多的啦
这里 对于数据的梳理 (对于数据的处理 我觉得也较通用)
特地 整理一个文档
0. 观察数据(其实很重要)

数据 有0 1 2 这样的离散数据 和 一些68fd1e64 80e26c9b fb936136 7b4723c4 不晓得是啥的数据
感觉能确定的是 第一列的数据 是标签数据
欧克 总结数据如下 有标签 离散 和 不晓得是啥的数据(先确定为连续数据吧)
按照习惯 其target一般特征后面
1. 读取数据
1 | # 标记 数据类型 |
1.1 标准数据查看三件套
1 | criteo_data.head() |
1.2 数据质量分析
- 查看缺失值
1 | criteo_data.isnull().sum() |
- 异常值分析
1 | # 查看==数值型列==的汇总统计 |
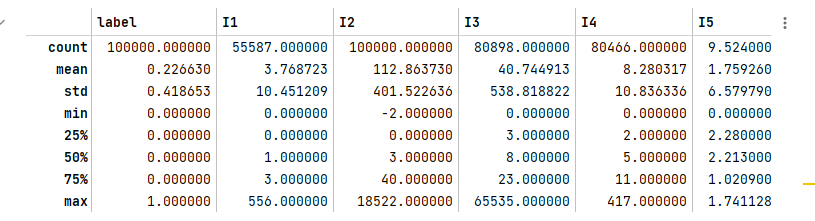
1.3 数据分类
1 | # 数据特征分为离散和连续类 |
2. 缺失值处理
针对缺失值 的 离散 和连续缺失的值 进行缺失值处理 (缺失一般是异常值)
一般是四步操作
- 查看变量类别
- 查看变量缺失值情况
- 对于缺失值进行标注
- 查看标注完缺失值情况
1 | # 查看离散变量目前的类别 |
1 | # 查看连续变量目前的类别 |
3. sklearn.preprocessing数据预处理
这里搬运一下 分箱的目的
- 离散变量便于特征的增加和减少,便于模型快速迭代
- 稀疏向量内积乘法更快,计算结果便于存储,容易扩展
- 离散化后的特征对异常数据有很强的鲁棒性,例如,连续异常值5000可能对模型影响很大,但如果分箱后,模型影响很小
- 为模型引入非线性,提升模型表达能力,加大拟合
- 模型更加稳定,不会因为各别数据增加而影响模型精度
- 简化模型,防止模型过拟合
3.1 处理连续型特征
在处理连续型特征 有两个方法 二值化 与 分段
- 二值化
二值化使用的类是 sklearn.preprocessing.Binarizer
根据阈值将数据二值化(将特征值设置为0或1),用于处理连续型变量。大于阈值的值映射为1,而小于或等于阈值的值映射为0。默认阈值为0时,特征中所有的正值都映射到1。二值化是对文本计数数据的常见操作,分析人员可以决定仅考虑某种现象的存在与否。
- 分段
分段使用的类 preprocessing.KBinsDiscretizer,相对麻烦点,给出下面的参数列表

1 | from sklearn.preprocessing import LabelEncoder, OrdinalEncoder, KBinsDiscretizer |
3.2 处理分类型特征
在机器学习中,大多数算法,譬如逻辑回归,支持向量机SVM,k近邻算法等都只能够处理数值型数据,不能处理文字,在sklearn当中,除了专用来处理文字的算法,其他算法在fit的时候全部要求输入数组或矩阵,也不能够导入文字型数据(其实手写决策树和普斯贝叶斯可以处理文字,但是sklearn中规定必须导入数值型)。
然而在现实中,许多标签和特征在数据收集完毕的时候,都不是以数字来表现的。比如说,学历的取值可以是[“小学”,“初中”,“高中”,“大学”],付费方式可能包含[“支付宝”,“现金”,“微信”]等等。在这种情况下,为了让数据适应算法和库,我们必须将数据进行编码,即是说,将文字型数据转换为数值型
文字型数据 转换成数字
1 | from sklearn.preprocessing import LabelEncoder, OrdinalEncoder, KBinsDiscretizer |
处理后的效果
[][qzetZn.md.png]

4. 划分标签和特征
1 | # 标签和数据换个位置 然后 去除col_names |
5. 划分训练,验证,测试集
1 | # 这里的意思是 大白话 |
5.1 数据划分
1 | train, valid_test = train_test_split(self.data, train_size=train_size, random_state=2021) |