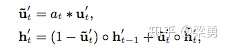感谢:
https://zh.d2l.ai/chapter_recurrent-modern/gru.html
https://zhuanlan.zhihu.com/p/48601882
https://zhuanlan.zhihu.com/p/103552262
https://zhuanlan.zhihu.com/p/78365283
最近比较迷茫,看了看自己的论文阅读表,这两篇阿里巴巴的文献映入眼帘,作为工业界的老大。其思维比较新颖。且较当时比较的模型有较大百分比的提升。CTR预测, 所谓的CTR,就是点击率Click Through Rate,而CTR预估算法在广告系统中起着至关重要的作用。从这两篇文章中可以看到阿里妈妈在深度学习方向上的探索,也可以窥视到阿里妈妈的CTR算法的发展脉络。
0. 一切从特征选取开始
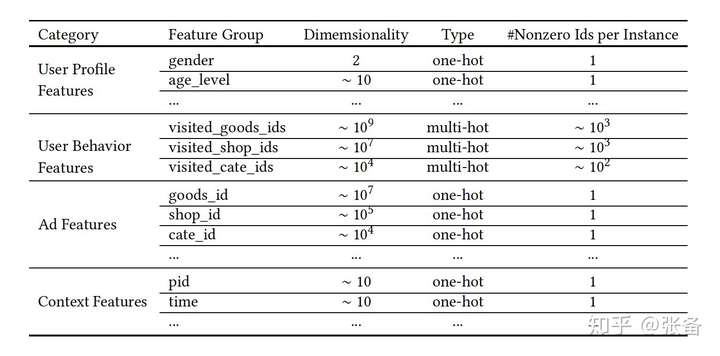
主要有4个特征组,如下图所示,
1)用户画像特征,
2)用户行为特征,即用户点击过的商品
3)待曝光的广告,广告其实也是商品,后文中我们统称为candidate
4)上下文特征。
1. 模型的鼻祖 (embedding + mlp)
如果说有10个商品的embedding,embedding的维度为16。在业界,pooling的处理方式就两个。
- sum pooling 对应的维度数字求和
- mean pooling 对应的维度数字求平均
1.1 问题
在电商这个场景中,通常用户的兴趣具有多样性,可能在一段时间内点击过衣服,电子产品,鞋子等。而对于不同的candidate来说,浏览过的相关商品对于预测帮助更大,不相关的商品对于ctr预估可能并不起作用,例如用户看过的衣服,鞋子对于iphone的预测并没有帮助
2. DIN
为了解决上述的问题,既然提到了相关,那肯定得考虑到==注意力机制==了啦
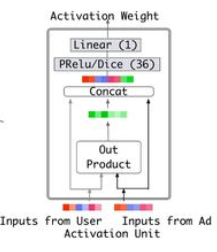
解决思路是: 在pooling的时候,与candidate相关的商品权重大一些,与candidate不相关的商品权重小一些,这是一种Attention的思想。将candidate与点击序列中的每个商品发生交互来计算attention分数。具体计算方法如图3中右上角的小网络所示,输入包括商品和candidate的embedding向量,以及两者的外积。对于不同的candidate,得到的用户表示向量也不同,具有更大的灵活性。
模型基础上 提出了Activation Unit单元 来提取商品与目标广告之间的相关性。 其中activation unit的输入包括两个部分,一个是原始的用户行为embedding向量、广告embedding向量;另外一个是两者Embedding向量经过外积计算后得到的向量,文章指出这种方式有利于relevance modeling。
2.1 attention归一化处理
一般来说,做attention的时候,需要对所有的分数通过softmax做归一化,这样做有两个好处,一是保证权重非负,二是保证权重之和为1。但是在DIN的论文中强调,不对点击序列的attention分数做归一化,直接将分数与对应商品的embedding向量做加权和,目的在于保留用户的兴趣强度。例如,用户的点击序列中90%是衣服,10%是电子产品,有一件T恤和一部手机需要预测CTR,那么T恤会激活大部分的用户行为,使得根据T恤计算出来的用户行为向量在数值上更大,相对手机而言。
2.2 DIN的创新点
DIN的论文中还提出了两个小的改进点。一个是对L2正则化的改进,在进行SGD优化的时候,每个mini-batch都只会输入部分训练数据,反向传播只针对部分非零特征参数进行训练,添加上L2之后,需要对整个网络的参数包括所有特征的embedding向量进行训练,这个计算量非常大且不可接受。论文中提出,在每个mini-batch中只对该batch的特征embedding参数进行L2正则化。第二个是提出了一个激活函数Dice。对于Relu或者PRelu来说,rectified point(梯度发生变化的点)都在0值,Dice对每个特征以mini-batch为单位计算均值和方差,然后将rectified point调整到均值位置。
3. DIEN
DIN在捕捉连续行为之间的依赖关系很弱,行为-》利益,其中隐性利益很难通过行为充分反映
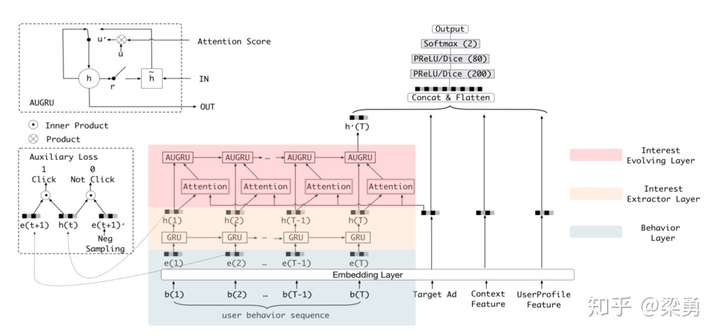
DIEN,全称是Deep Interest Evolution Network,即用户兴趣进化网络。这个算法中用两层架构来抽取和使用用户兴趣特征:
- 兴趣抽取层Interest Extractor Layer: 从用户行为序列中提取信息
- 兴趣进化层Interest Evolving Layer: 从用户行为序列中找到目标相关的兴趣,对其进行建模
3.1 兴趣抽取层(这里使用的是GRU)
在广告与商品之间并不是单纯的商品对应的关系(即我喜欢的是这个)
兴趣抽取层Interest Extractor Layer的主要目标是从embedding数据中提取出interest。但一个用户在某一时间的interest不仅与当前的behavior有关,也与之前的behavior相关,所以作者们使用GRU单元来提取interest。GRU单元的表达式如下。 其中,σ是sigmoid操作,而◦是内积操作。
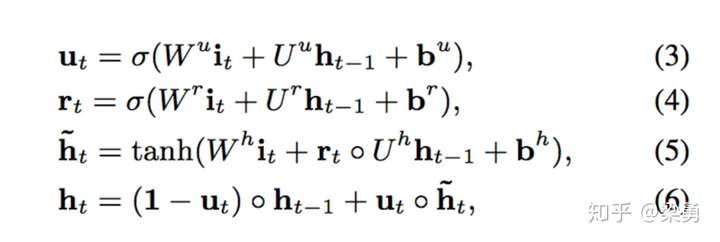
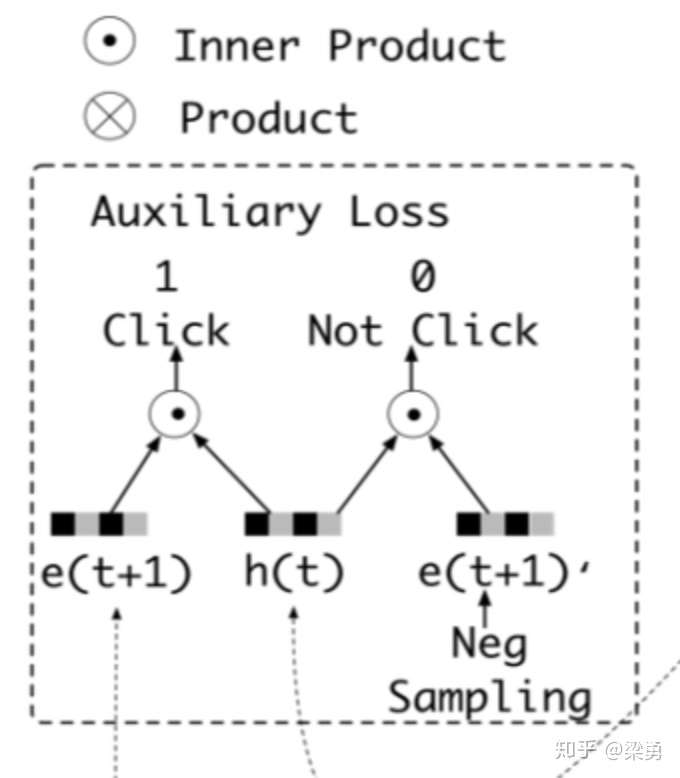
- 作者的辅助测试
作者设计了一个二分类模型来计算兴趣抽取的准确性,我们将用户下一时刻真实的行为e(t+1)作为正例,负采样得到的行为作为负例e(t+1)’,分别与抽取出的兴趣h(t)结合输入到设计的辅助网络中,得到预测结果,并通过logloss计算一个辅助的损失
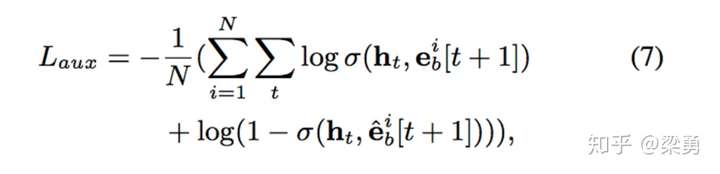
3.2 兴趣进化层 (带有注意力的GRU)
- interest在变化过程中遵循如下规律:
1)interest drift:用户在某一段时间的interest会有一定的集中性。比如用户可能在一段时间内不断买书,在另一段时间内不断买衣服。
2)interest individual:一种interest有自己的发展趋势,不同种类的interest之间很少相互影响,例如买书和买衣服的interest基本互不相关。
3.2.1 attention机制
兴趣抽取层获得的隐向量,ht 与 被embedding后的广告向量 产生内积后softmax取相关参数
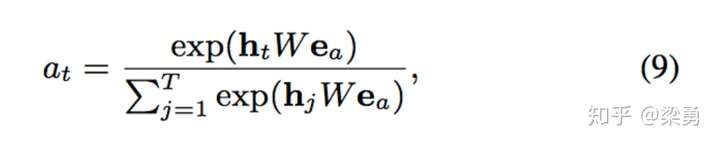
3.2.2 attention方式
- GRU with attentional input (AIGRU)
这种方式将attention直接作用于输入,无需修改GRU的结构:
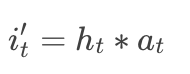
- Attention based GRU(AGRU)
这种方式需要修改GRU的结构,此时hidden state的输出变为:
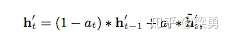
- GRU with attentional update gate (AUGRU)
这种方式需要修改GRU的结构,此时hidden state的输出变为: