感谢:https://zhuanlan.zhihu.com/p/32085405
文章 写的怪好的 但是 在博客的体现并不怎么好看 如果想看 去看md文档
0. RNN
先简单介绍一下一般的RNN。
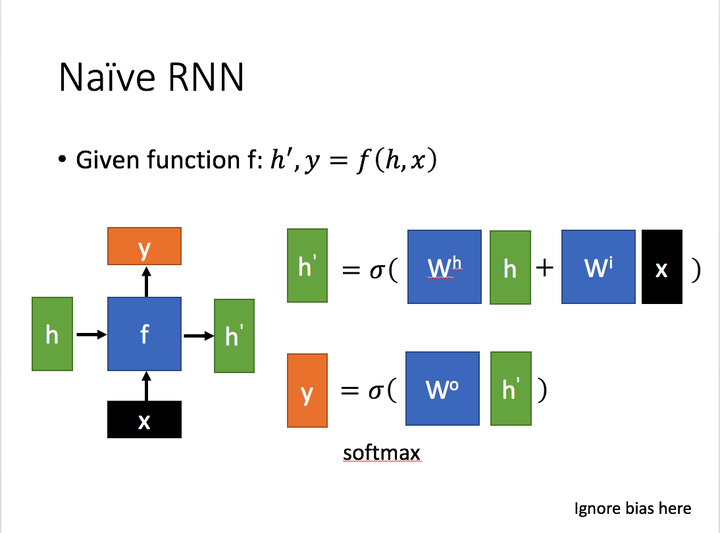
这里:
x为当前状态下数据的输入, h表示接收到的上一个节点的输入。
y为当前节点状态下的输出,而**h’**为传递到下一个节点的输出。
通过上图的公式可以看到,输出 h’ 与 x 和 h 的值都相关。
而 y 则常常使用 h’ 投入到一个线性层(主要是进行维度映射)然后使用softmax进行分类得到需要的数据。
对这里的y如何通过 h’ 计算得到往往看具体模型的使用方式。
通过序列形式的输入,我们能够得到如下形式的RNN。
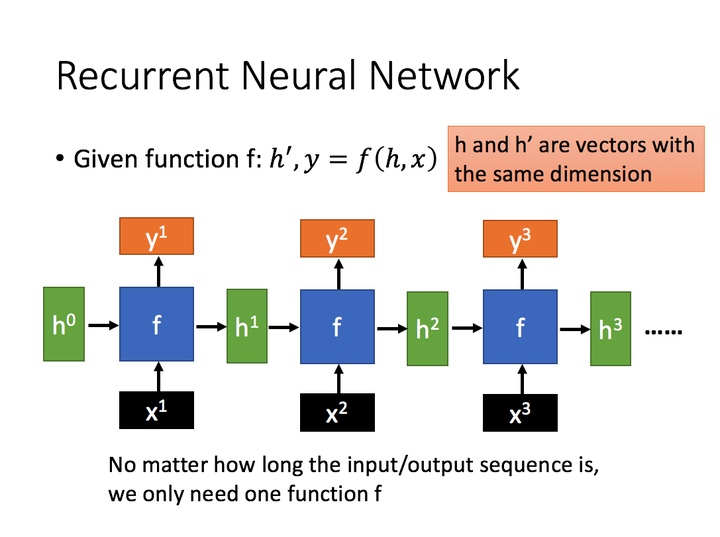
1. LSTM
长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
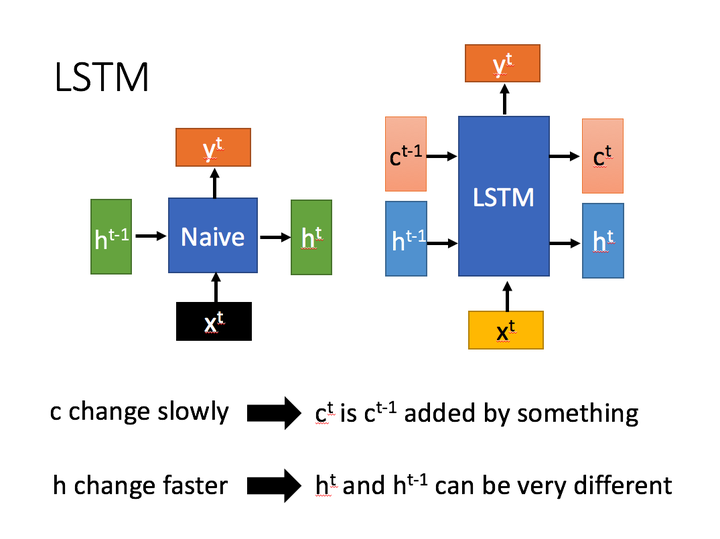
相比RNN只有一个传递状态 ,LSTM有两个传输状态,一个
(cell state),和一个
(hidden state)。(Tips:RNN中的
对于LSTM中的
)
其中对于传递下去的 改变得很慢,通常输出的
是上一个状态传过来的
加上一些数值。
而 则在不同节点下往往会有很大的区别。
1.1 LSTM 结构深入
下面具体对LSTM的内部结构来进行剖析。
首先使用LSTM的当前输入 和上一个状态传递下来的
拼接训练得到四个状态。
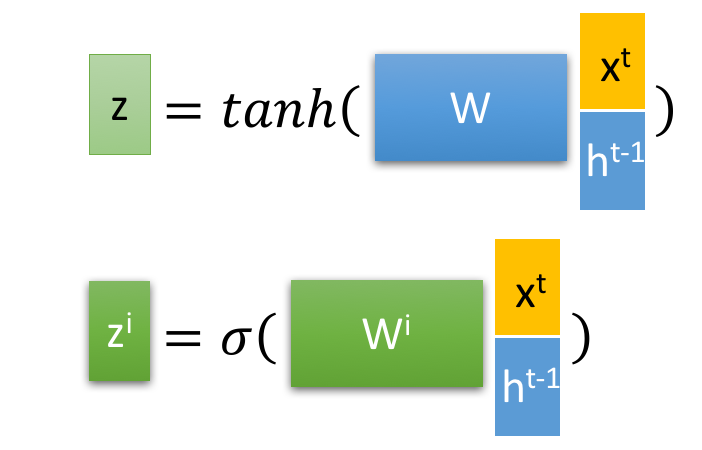
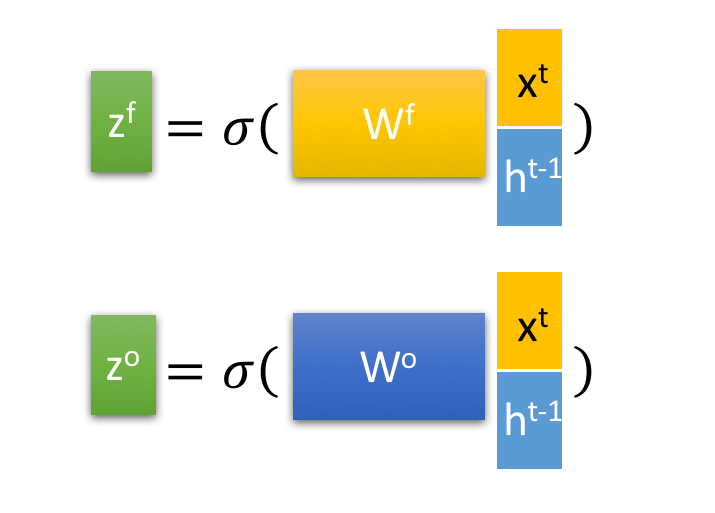
其中, ,
,
是由拼接向量乘以权重矩阵之后,再通过一个
激活函数转换成0到1之间的数值,来作为一种门控状态。而
则是将结果通过一个
激活函数将转换成-1到1之间的值(这里使用
是因为这里是将其做为输入数据,而不是门控信号)
下面开始进一步介绍这四个状态在LSTM内部的使用。(敲黑板)
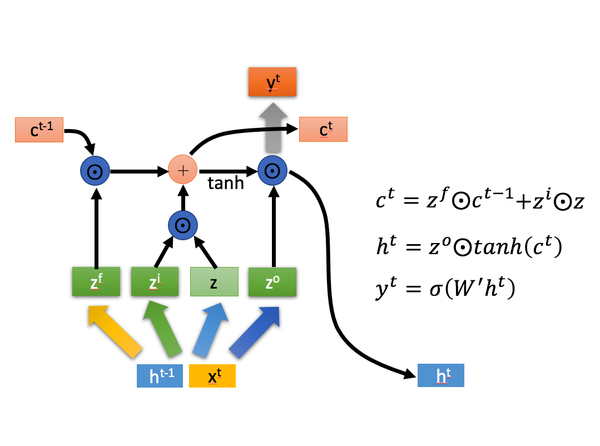
其经典图片是这样的

1.2 主要的阶段
LSTM内部主要有三个阶段:
- 忘记阶段。这个阶段主要是对上一个节点传进来的输入进行选择性忘记。简单来说就是会 “忘记不重要的,记住重要的”。
具体来说是通过计算得到的 (f表示forget)来作为忘记门控,来控制上一个状态的
哪些需要留哪些需要忘。
- 选择记忆阶段。这个阶段将这个阶段的输入有选择性地进行“记忆”。主要是会对输入
进行选择记忆。哪些重要则着重记录下来,哪些不重要,则少记一些。当前的输入内容由前面计算得到的
表示。而选择的门控信号则是由
(i代表information)来进行控制。
将上面两步得到的结果相加,即可得到传输给下一个状态的
。也就是上图中的第一个公式。
- 输出阶段。这个阶段将决定哪些将会被当成当前状态的输出。主要是通过
来进行控制的。并且还对上一阶段得到的
进行了放缩(通过一个tanh激活函数进行变化)。
与普通RNN类似,输出 往往最终也是通过
变化得到。
1.3 总结
以上,就是LSTM的内部结构。通过门控状态来控制传输状态,记住需要长时间记忆的,忘记不重要的信息;而不像普通的RNN那样只能够“呆萌”地仅有一种记忆叠加方式。对很多需要“长期记忆”的任务来说,尤其好用。
但也因为引入了很多内容,导致参数变多,也使得训练难度加大了很多。因此很多时候我们往往会使用效果和LSTM相当但参数更少的GRU来构建大训练量的模型。
2. GRU
GRU(Gate Recurrent Unit)是循环神经网络(Recurrent Neural Network, RNN)的一种。和LSTM(Long-Short Term Memory)一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的 。
其性能与LSTM相当 ,但是 其计算的消耗较前者少。

2.1 输入输出
GRU的输入输出结构与普通的RNN是一样的。
有一个当前的输入 ,和上一个节点传递下来的隐状态(hidden state)
,这个隐状态包含了之前节点的相关信息。
结合 和
,GRU会得到当前隐藏节点的输出
和传递给下一个节点的隐状态
。

2.2 内部结构
通过上一个传输下来的状态 和当前节点的输入
来获取两个门控状态。 其中
控制重置的门控(reset gate),
为控制更新的门控(update gate)。

得到门控信号之后,首先使用重置门控来得到“重置”之后的数据 ,再将
与输入
进行拼接,再通过一个tanh激活函数来将数据放缩到**-1~1**的范围内。即得到如下图2-3所示的
。

这里的 主要是包含了当前输入的
数据。有针对性地对
添加到当前的隐藏状态,相当于”记忆了当前时刻的状态“。

最后介绍GRU最关键的一个步骤,我们可以称之为”更新记忆“阶段。
在这个阶段,我们同时进行了遗忘了记忆两个步骤。我们使用了先前得到的更新门控 (update gate)。
更新表达式:
首先再次强调一下,门控信号(这里的 )的范围为0~1。门控信号越接近1,代表”记忆“下来的数据越多;而越接近0则代表”遗忘“的越多。
有读者发现在pytorch里面的GRU[链接]写法相比原版对
多了一个映射,相当于一个GRU变体,猜测是多加多这个映射能让整体实验效果提升较大。如果有了解的同学欢迎评论指出。
GRU很聪明的一点就在于,我们使用了同一个门控 就同时可以进行遗忘和选择记忆(LSTM则要使用多个门控)。
:表示对原本隐藏状态的选择性“遗忘”。这里的
可以想象成遗忘门(forget gate),忘记
: 表示对包含当前节点信息的
进行选择性”记忆“。与上面类似,这里的
同理会忘记
维度中的一些不重要的信息。或者,这里我们更应当看做是对
维度中的某些信息进行选择。
:结合上述,这一步的操作就是忘记传递下来的
中的某些维度信息,并加入当前节点输入的某些维度信息。
可以看到,这里的遗忘
和选择
2.3 总结
GRU输入输出的结构与普通的RNN相似,其中的内部思想与LSTM相似。
与LSTM相比,GRU内部少了一个”门控“,参数比LSTM少,但是却也能够达到与LSTM相当的功能。考虑到硬件的计算能力和时间成本,因而很多时候我们也就会选择更加”实用“的GRU啦。