1. 深度学习推荐模型(2)
2.4 FM与深度学习模型
2.4.1 FNN - 用FM的隐向量完成embedding层初始化

FNN相较于deep crossing模型的区别
- 对于embedding进行了改进,在模型初始化时引入了有价值的先验信息

- 在训练时特征被划分了不同的特征域,每个特征域有对应的embedding层
2.4.2 deepFM(啊哈哈 大怨种来啦)
究竟是怎样的大佬 看得懂我下面这句话 反正我是看不懂的
强调 红色为 权重1连接 就是是啥就是啥
用FM代替wide部分
FM部分
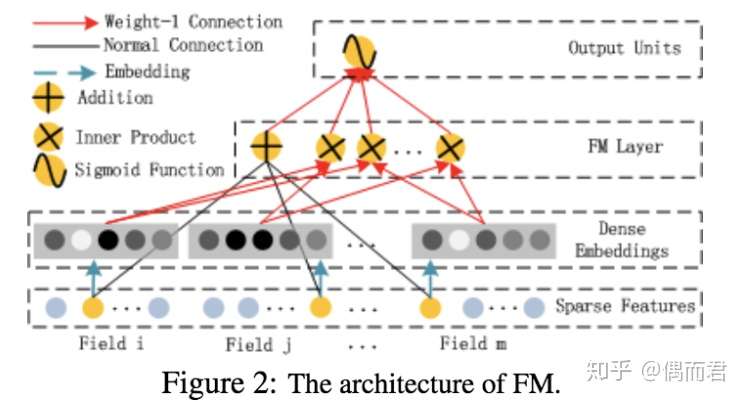
这个FM layer 在图上面 直观的看啊 有 一个+ 和 好多个 * 这个+ 是 FM层 的线性部分
这个*呢 就是 FM层的 特征组合部分(这里应该是 vi 点积 vj)
其输出公式为
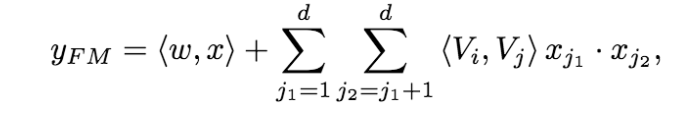
deep 部分
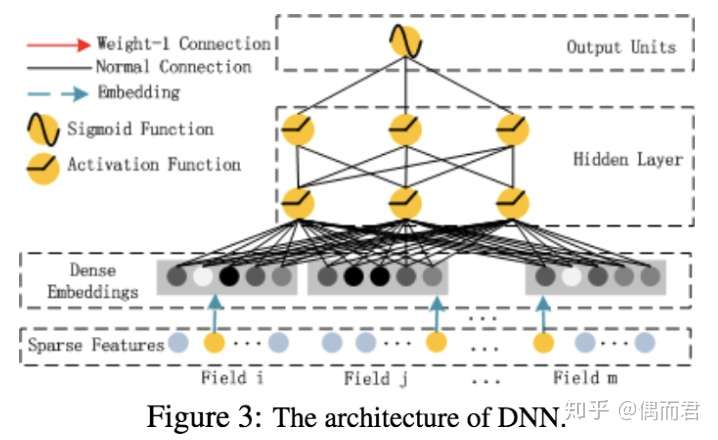
这个deep部分啊
就是多层感知机嘛 没啥难的
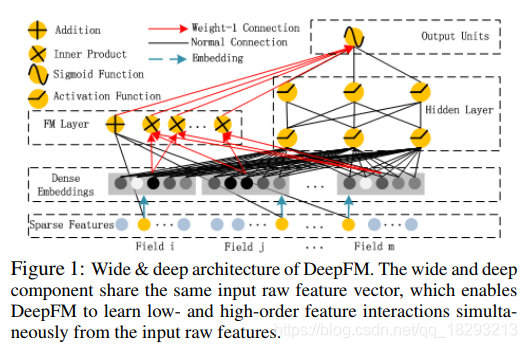
FM与深度模型的组合有两种,一种是二者并行,另一种是二者串行。DeepFM就是并行的一种结构。并行就是FM将输入部分计算完之后单独拿出来,得到一组特征表示,然后再利用深度模型(多层全连接)对输入部分进行高阶的特征组合。最后把二者的特征进行concact,得到一组特征,最后对这组特征进行分类或者回归。其实这只是特征的一种组合方式,目的就是为了得到特征的高阶表示。
输出公式
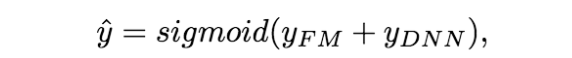
细节(权重共用) 下面解释好好的看
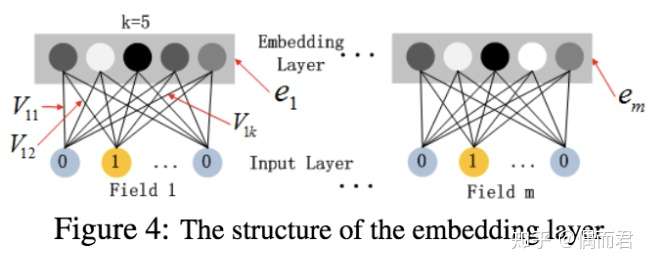
这里的第二点如何理解呢,假设我们的k=5,首先,对于输入的一条记录,同一个field 只有一个位置是1,那么在由输入得到dense vector的过程中,输入层只有一个神经元起作用,得到的dense vector其实就是输入层到embedding层该神经元相连的五条线的权重,即vi1,vi2,vi3,vi4,vi5。这五个值组合起来就是我们在FM中所提到的Vi。在FM部分和DNN部分,这一块是共享权重的,对同一个特征来说,得到的Vi是相同的。
2.4.3 总结
特征工程在这条路上已经穷尽了可能性的尝试,模型的提升空间会非常小。但是很重要
2.5 注意力机制的应用
https://blog.csdn.net/wuzhongqiang/article/details/109532346
- Attention机制的本质
attention机制的本质是从人类视觉注意力机制中获得灵感(可以说很‘以人为本’了)。大致是我们视觉在感知东西的时候,一般不会是一个场景从到头看到尾每次全部都看,而往往是根据需求观察注意特定的一部分。而且当我们发现一个场景经常在某部分出现自己想观察的东西时,我们就会进行学习在将来再出现类似场景时把注意力放到该部分上。这可以说就是注意力机制的本质内容了。至于它本身包含的‘自上而下’和‘自下而上’方式就不在过多的讨论。
- Attention机制的理解
Attention机制其实就是一系列注意力分配系数,也就是一系列权重参数罢了。
2.5.1 AFM - 引入注意力机制的FM
注意力网络的作用是为每一个交叉特征提供权重
2.5.2 DIN
https://blog.csdn.net/Blank_spaces/article/details/106485534
basemodel
基本模型是获得一个固定长度的用户的表示向量,但不管候选广告是什么,此表示向量对于给定用户均保持不变。这样,维度受限的用户表示向量将成为表达用户多样化兴趣的瓶颈
DIN通过给定一个候选广告,然后去注意与该广告相关的局部兴趣的表示来模拟此过程。DIN不会通过使用同一向量来表达所有用户的不同兴趣,而是通过考虑历史行为的相关性来自适应地计算用户兴趣的表示向量(对于给定的广告)。 
注意力在其上面的形式是激活单元来生成注意力得分