说些废话
链接:https://www.bilibili.com/video/BV11L411j7sX
https://www.kaggle.com/competitions/elo-merchant-category-recommendation
比赛 很不错 但是 现在 没有时间去看
数据分析
1. 数据解读
1 | import pandas as pd |
上面的操作就很easy
1 | # 观察头5行的情况 |
2. 数据质量分析
接下来简单数据探索。在实际建模过程中,首先我们会先校验数据的正确性,并检验缺失值、异常值等情况。
数据正确性校验
所谓数据正确性,指的是数据本身是否符合基本逻辑,例如此处信用卡id作为建模分析对象独一无二的标识,我们需要验证其是否确实独一无二,并且训练集和测试集信用卡id无重复。1
2train['card_id'].nunique() == train.shape[0]
test['card_id'].nunique() == test.shape[0]判断缺失值情况
1 | # 按列求缺失值并汇总 |
3. 异常值分析
- describe()方法
异常值检验。由于我们尚未对数据集特征进行预处理,因此我们先查看标签列的异常值情况。首先我们可以用describe()方法查看这一列的基本统计信息:
1 | # 使用describe()方法查看这一列的基本统计信息 |
- 通过直方图观察
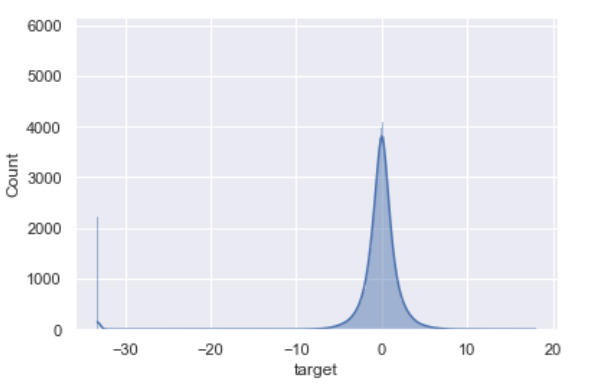
由于是连续变量可以借助概率密度直方图进行分布的观察:
1 | import seaborn as sns |
- $3\delta$原则进行异常值识别
能够发现,大部分用户忠诚度评分都集中在[-10,10]之间,并且基本符合正态分布,唯一需要注意的是有个别异常值取值在-30以下,该数据在后续分析中需要额外注意。我们可以简单查看有多少用户的标签数值是小于30的:
当然,对于连续变量,一般可以采用$3\delta$原则进行异常值识别,此处我们也可以简单计算下异常值范围:
1 | statistics.loc['mean'] - 3 * statistics.loc['std'] |
  需要注意的是,此处我们是围绕标签进行的异常值检测,而本案例中标签并不是自然数值测量或统计的结果(如消费金额、身高体重等),而是通过某种公式人工计算得出(详见赛题分析)。出现如此离群点极有可能是某类特殊用户的标记。因此不宜进行异常值处理,而应该将其单独视作特殊的一类,在后续建模分析时候单独对此类用户进行特征提取与建模分析。
4. 规律一致性分析
  接下来,进行训练集和测试集的规律一致性分析。
  所谓规律一致性,指的是需要对训练集和测试集特征数据的分布进行简单比对,以“确定”两组数据是否诞生于同一个总体,即两组数据是否都遵循着背后总体的规律,即两组数据是否存在着规律一致性。
  我们知道,尽管机器学习并不强调样本-总体的概念,但在训练集上挖掘到的规律要在测试集上起到预测效果,就必须要求这两部分数据受到相同规律的影响。一般来说,对于标签未知的测试集,我们可以通过特征的分布规律来判断两组数据是否取自同一总体
- 单变量分析
1 | # 特征列名 |
1 | # 分布图如下所示: |
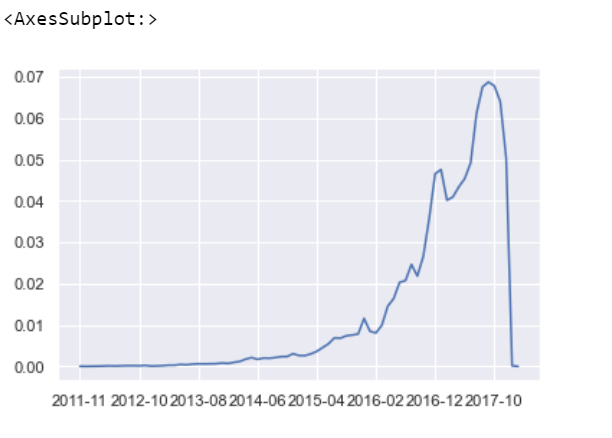
当然,我们需要同时对比训练集和测试集的四个特征,可以通过如下代码实现:
1 | for feature in features: |
- 多级联合分布
接下来,我们进一步查看联合变量分布。所谓联合概率分布,指的是将离散变量两两组合,然后查看这个新变量的相对占比分布。例如特征1有0/1两个取值水平,特征2有A/B两个取值水平,则联合分布中就将存在0A、0B、1A、1B四种不同取值水平,然后进一步查看这四种不同取值水平出现的分布情况。
实际建模过程中,规律一致性分析是非常重要但又经常容易被忽视的一个环节。通过规律一致性分析,我们可以得出非常多的可用于后续指导后续建模的关键性意见。通常我们可以根据规律一致性分析得出以下基本结论
作用:
- 如果分布非常一致,则说明所有特征均取自同一整体,训练集和测试集规律拥有较高一致性,模型效果上限较高,建模过程中应该更加依靠特征工程方法和模型建模技巧提高最终预测效果
- 如果分布不太一致,则说明训练集和测试集规律不太一致,此时模型预测效果上限会受此影响而被限制,并且模型大概率容易过拟合,在实际建模过程中可以多考虑使用交叉验证等方式防止过拟合,并且需要注重除了通用特征工程和建模方法外的trick的使用;